Автор: Денис Аветисян
Новая архитектура AR-Omni позволяет генерировать данные в любой модальности, используя единую авторегрессионную модель без специализированных декодеров.
Исследователи представили универсальную модель для обработки и генерации мультимодальных данных с возможностью потоковой генерации речи в реальном времени.
Несмотря на прогресс в области мультимодальных больших языковых моделей, большинство систем по-прежнему полагаются на специализированные компоненты для генерации различных типов данных. В данной работе представлена модель ‘AR-Omni: A Unified Autoregressive Model for Any-to-Any Generation’, предлагающая унифицированный авторегрессионный подход к генерации текста, изображений и речи, исключающий необходимость в отдельных декодерах для каждой модальности. AR-Omni обеспечивает конкурентоспособное качество генерации во всех трех модальностях, достигая работы в реальном времени для синтеза речи с фактором 0.88. Какие перспективы открываются для дальнейшего развития унифицированных архитектур и преодоления разрыва между различными типами данных в задачах искусственного интеллекта?
Разрушая Границы: Эволюция Мультимодального Искусственного Интеллекта
В последние годы наблюдается значительный прогресс в области искусственного интеллекта, в частности, расширение возможностей больших языковых моделей (LLM) для обработки мультимодальных данных. Изначально ориентированные на текст, эти модели теперь способны анализировать и генерировать контент, объединяя информацию из различных источников, таких как изображения и аудио. Это привело к появлению мощных мультимодальных больших языковых моделей, способных к более комплексному пониманию и взаимодействию с окружающим миром. Благодаря использованию новых архитектур и методов обучения, эти модели демонстрируют впечатляющие результаты в задачах, требующих интеграции различных типов данных, открывая новые перспективы для развития искусственного интеллекта и его применения в самых разных областях — от автоматизированной обработки контента до создания более интеллектуальных и интуитивно понятных интерфейсов.
Эффективная интеграция различных модальностей — текста, изображений и аудио — представляет собой серьезные трудности для современных искусственных интеллектов. Основная проблема заключается в том, как наилучшим образом представить данные, поступающие из разных источников, в едином формате, понятном для модели. Простое объединение данных часто приводит к потере важной информации или искажению связей между ними. Кроме того, масштабирование моделей для обработки и анализа огромных объемов мультимодальных данных требует значительных вычислительных ресурсов и разработки новых алгоритмов, способных эффективно использовать эти ресурсы. Сложность заключается не только в увеличении размера модели, но и в поддержании ее способности к обобщению и предотвращению переобучения на конкретном наборе данных, что особенно актуально при работе с разнородными данными, где корреляции могут быть скрытыми или неявными.
Первые модели, такие как Chameleon, продемонстрировали перспективные результаты в области обработки различных типов данных — текста, изображений и звука. Однако, их возможности были ограничены сложностью создания единой системы, способной эффективно обрабатывать и генерировать информацию, объединяя разные модальности. Несмотря на способность распознавать связи между различными входными сигналами, Chameleon испытывал трудности при создании связного и осмысленного контента, комбинирующего, например, текстовое описание с визуальным представлением. Проблема заключалась в том, что модель не всегда могла установить глубокие семантические связи между различными модальностями, что приводило к несогласованности в генерируемых ответах и ограничению её способности к полноценному мультимодальному рассуждению.

AR-Omni: Унифицированный Авторегрессионный Подход
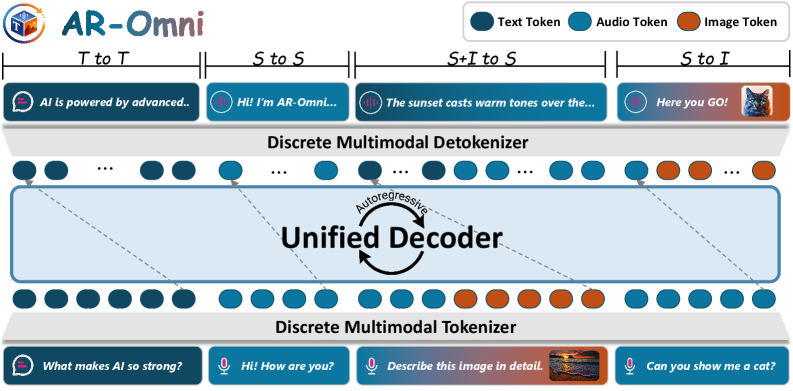
AR-Omni представляет собой ключевое решение, использующее авторегрессионное моделирование для создания унифицированной структуры генерации мультимодальных данных. Данный подход позволяет осуществлять генерацию любого типа данных из любого другого типа, объединяя текст, изображения и аудио в единую систему. В отличие от традиционных методов, требующих отдельных декодеров для каждой модальности, AR-Omni использует единую модель для обработки и генерации данных, что значительно упрощает процесс и снижает вычислительные затраты. Это достигается за счет представления всех типов данных в виде последовательности дискретных токенов, что позволяет модели обучаться на смешанных данных и генерировать согласованные мультимодальные выходные данные.
В основе AR-Omni лежит дискретная токенизация, процесс преобразования данных из различных модальностей — текста, изображений и аудио — в общую последовательность дискретных токенов. Это достигается путем квантизации непрерывных данных в дискретные представления, что позволяет объединить разнородные типы данных в единое пространство. В результате, каждый тип модальности представляется как последовательность токенов, пригодная для обработки единой авторегрессионной моделью. Такой подход позволяет избежать необходимости в отдельных декодерах для каждой модальности и обеспечивает бесшовную интеграцию и взаимодействие между ними.
Использование единой авторегрессионной модели в AR-Omni позволяет отказаться от необходимости в отдельных декодерах для каждой модальности. Традиционно, генерация мультимодального контента требовала отдельных декодеров для текста, изображений и аудио, что приводило к увеличению вычислительной сложности и затрат памяти. Устранение отдельных декодеров значительно упрощает процесс генерации, снижая вычислительную нагрузку и потребление ресурсов, поскольку все модальности обрабатываются единой моделью на основе общего дискретного представления. Это приводит к более эффективному и масштабируемому решению для генерации мультимодального контента.
В основе AR-Omni лежит концепция единого словарного запаса (Joint Vocabulary), объединяющего токенизированные данные всех модальностей — текста, изображений и аудио — в единое пространство токенов. Это означает, что каждый элемент данных, независимо от его исходной модальности, представляется одним из токенов в этом общем словаре. Использование единого словаря критически важно для обеспечения согласованного взаимодействия между модальностями, поскольку позволяет модели напрямую предсказывать токены любой модальности на основе токенов других модальностей без необходимости в дополнительных преобразованиях или адаптациях. Такой подход упрощает архитектуру модели и повышает эффективность генерации мультимодального контента.

Решение Проблемы Дисбаланса Модальностей и Оптимизация Производительности
Проблема дисбаланса модальностей является критичным фактором при обучении мультимодальных моделей. Данный дисбаланс возникает из-за различий в объеме токенов, необходимых для представления данных различных модальностей (например, текста, аудио, изображений), или из-за особенностей кодирования данных. Модальность с большим количеством токенов или более информативным представлением может доминировать в процессе обучения, подавляя вклад других модальностей и приводя к снижению общей производительности модели. Это требует применения специальных техник для нормализации вклада каждой модальности и обеспечения сбалансированного обучения.
Для решения проблемы дисбаланса модальностей в процессе обучения, AR-Omni использует методы взвешенного нормализованного преобразования признаков (Weighted NTP) и взвешивания, ориентированного на задачу (Task-Aware Reweighting). Weighted NTP динамически регулирует вклад каждой модальности на основе её значимости для конкретной задачи, предотвращая доминирование одной модальности над другими. Task-Aware Reweighting дополнительно адаптирует веса модальностей в зависимости от специфики решаемой задачи, оптимизируя общий результат и обеспечивая более сбалансированное использование информации из различных источников. Данные методы позволяют эффективно учитывать вклад каждой модальности, улучшая общую производительность и стабильность модели.
В AR-Omni для токенизации аудио используются эффективные кодеки SoundStream и EnCodec, позволяющие сжать аудиоданные в дискретное представление, пригодное для обработки моделью. Параллельно для токенизации изображений применяются VQ-VAE и VQGAN, которые также преобразуют изображения в компактные векторные токены. Использование этих кодеков позволяет снизить вычислительные затраты и объем памяти, необходимые для обработки мультимодальных данных, при этом сохраняя приемлемое качество реконструкции и генерации.
Для повышения геометрической согласованности в визуальном токенизированном пространстве, в AR-Omni внедрена функция потерь, основанная на восприятии (Perceptual Loss). Данная функция оценивает разницу между сгенерированным и целевым изображением не на уровне отдельных пикселей, а с точки зрения восприятия, используя признаки, извлеченные из предварительно обученной нейронной сети. Это позволяет модели генерировать изображения с более высоким уровнем детализации и реалистичности, улучшая их визуальное качество и согласованность с другими модальностями. Использование Perceptual Loss способствует формированию более связного и правдоподобного визуального представления, что особенно важно для задач генерации мультимодального контента.
В ходе тестирования AR-Omni продемонстрировала возможность обработки потоковой речи в режиме реального времени. Показатель задержки первого токена (First Token Latency, FTL) составил 146 миллисекунд, что характеризует скорость генерации начального ответа. Коэффициент реального времени (Real-Time Factor, RTF) равен 0.88, указывая на то, что обработка занимает 88% от времени, необходимого для проигрывания аудио в реальном времени. Данные метрики подтверждают эффективность архитектуры AR-Omni для приложений, требующих минимальной задержки и высокой пропускной способности.

Стратегии Декодирования и Перспективы Развития
В основе AR-Omni лежит механизм декодирования на основе конечного автомата, позволяющий динамически переключаться между жадным (greedy) и вероятностным (sampling) подходами в процессе генерации. Такая адаптивность позволяет оптимизировать баланс между когерентностью и разнообразием создаваемых данных, в зависимости от конкретной задачи. В ситуациях, требующих высокой точности и предсказуемости, используется жадный подход, обеспечивающий наиболее вероятный результат. Когда же важна креативность и вариативность, система переходит на вероятностное декодирование, исследуя более широкий спектр возможных вариантов. Этот механизм позволяет AR-Omni эффективно справляться с различными типами задач, генерируя как точные, так и оригинальные результаты, приближая систему к более интеллектуальному и гибкому взаимодействию с данными.
Для повышения стабильности обучения и возможности масштабирования модели AR-Omni была внедрена техника нормализации Swin-Norm, представляющая собой нормализацию после остаточного соединения. В отличие от традиционных методов, применяемых до остаточного соединения, Swin-Norm позволяет более эффективно обрабатывать градиенты в глубоких нейронных сетях, предотвращая проблему затухания или взрыва градиентов. Этот подход особенно важен при обучении крупных моделей, где нестабильность обучения может существенно замедлить процесс и снизить качество полученных результатов. Благодаря Swin-Norm, AR-Omni демонстрирует повышенную устойчивость к изменениям гиперпараметров и позволяет эффективно обучать модели с большим количеством параметров, открывая путь к созданию более сложных и мощных систем искусственного интеллекта.
В основе AR-Omni лежит принципиально новый подход к обработке информации, объединяющий различные модальности — текст, речь, изображение — в единую систему генерации. Это позволяет модели не просто понимать отдельные типы данных, но и устанавливать между ними сложные взаимосвязи, создавая целостное представление о мире. Подобная унификация открывает перспективы для создания действительно интеллектуальных систем, способных к беспрепятственному взаимодействию с человеком и окружающей средой через любые каналы коммуникации. В отличие от традиционных моделей, специализирующихся на отдельных задачах, AR-Omni стремится к универсальности, представляя собой шаг к созданию искусственного интеллекта, способного к комплексному восприятию и генерации информации в различных форматах, что является ключевым элементом для построения по-настоящему «умных» устройств и приложений.
Результаты тестирования модели AR-Omni демонстрируют высокую производительность в задачах обработки речи. В частности, при синтезе речи (TTS) на наборе данных VCTK достигнут показатель Word Error Rate (WER) в 6.5%, что свидетельствует о качественной и разборчивой генерации звука. В задачах автоматического распознавания речи (ASR) на тестовом наборе LibriSpeech test-clean, модель показала WER в 9.4%, подтверждая её способность точно преобразовывать речь в текст. Данные метрики указывают на значительный прогресс в области мультимодальных систем и открывают возможности для создания более совершенных голосовых помощников и инструментов транскрипции.
Дальнейшие исследования AR-Omni сосредоточены на расширении его возможностей до генерации видео, опираясь на успехи, продемонстрированные моделью MIO. Параллельно проводится работа над оптимизацией стратегий токенизации, направленная на повышение эффективности обработки данных и снижение вычислительных затрат. Цель состоит в том, чтобы не только улучшить производительность модели в существующих задачах, но и создать основу для её адаптации к более сложным и ресурсоемким мультимодальным приложениям, где обработка видео играет ключевую роль. Успешная реализация этих направлений позволит AR-Omni стать более универсальной и масштабируемой платформой для создания интеллектуальных систем, способных к комплексному взаимодействию с окружающим миром.

Исследование представляет собой попытку создать универсальную систему, способную оперировать различными типами данных — текстом, изображениями и речью — в рамках единой архитектуры. Подобный подход, не требующий отдельных декодеров для каждой модальности, напоминает о словах Марвина Минского: «Искусственный интеллект — это не создание машин, которые думают, а создание машин, которые делают так, чтобы люди думали». AR-Omni демонстрирует, что объединение различных модальностей в единую систему позволяет не только достичь конкурентоспособных результатов, но и открыть возможности для потоковой генерации речи в реальном времени, что подчеркивает стремление к созданию действительно интеллектуальных систем, способных адаптироваться и взаимодействовать с миром подобно человеку.
Куда же дальше?
Представленная архитектура, безусловно, элегантна в своей универсальности. Однако, увлечение единым принципом генерации для столь разнородных данных неминуемо наталкивается на вопрос эффективности. Достигнута ли истинная конвергенция, или же универсальность — это просто умелая маскировка компромиссов? Вероятно, дальнейшие исследования будут сосредоточены на тонкой настройке дискретной токенизации для каждой модальности, чтобы выжать максимум из ограниченных ресурсов и избежать размывания специфических характеристик данных.
Особый интерес представляет возможность потоковой генерации речи. Здесь возникает соблазн уйти от чисто авторегрессивного подхода, исследуя параллельные методы декодирования, чтобы сократить задержки и приблизиться к реальному времени. Но, разумеется, любая оптимизация — это всегда игра с дьяволом, и за скорость придется заплатить точностью или выразительностью.
В конечном счете, AR-Omni — это лишь еще один шаг на пути к пониманию того, как устроена реальность. Истинная задача не в создании универсальной модели, а в деконструкции самой концепции «данных», в выявлении фундаментальных принципов, лежащих в основе любого сигнала, будь то текст, изображение или звук. А это, как известно, требует не только вычислительной мощности, но и изрядной доли скептицизма.
Оригинал статьи: https://arxiv.org/pdf/2601.17761.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS/USD
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-01-27 07:25