Автор: Денис Аветисян
Новое исследование выявляет узкие места в навыках языковых моделей, ограничивающие их способность эффективно действовать в сложных, многоэтапных задачах.

Предлагаемый фреймворк LUMINA использует управляемые вмешательства и процедурно генерируемые среды для анализа планирования, отслеживания состояния и управления историей в задачах с многоходовым взаимодействием.
Несмотря на успехи больших языковых моделей в решении отдельных задач, создание агентов, способных к эффективному взаимодействию в многошаговых сценариях, остается сложной проблемой. В работе ‘LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents’ предложен оригинальный подход к анализу ключевых ограничений, препятствующих развитию таких агентов. Используя процедурно генерируемые среды и так называемые «оракулы» — идеальные реализации отдельных навыков, авторы выявили, что значимость планирования и отслеживания состояния зависит от конкретных условий и возможностей языковой модели. Какие новые методы позволят преодолеть эти ограничения и создать по-настоящему интеллектуальных агентов, способных к долгосрочному планированию и адаптивному взаимодействию?
Временные Границы Рассуждений: Вызовы Долгосрочного Планирования
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие возможности в обработке и генерации текста, однако сталкиваются с существенными трудностями при решении задач, требующих долгосрочного планирования и последовательных действий. В то время как БЯМ преуспевают в краткосрочных предсказаниях и ответах на прямые вопросы, их способность к разработке сложных стратегий, требующих множества шагов и учета отдаленных последствий, ограничена. Эта проблема проявляется в задачах, где необходимо учитывать изменяющиеся условия, прогнозировать результаты действий на несколько шагов вперед и адаптироваться к неожиданным обстоятельствам. Например, БЯМ могут генерировать связный текст рассказа, но испытывают трудности в планировании сложной сюжетной линии, требующей последовательного развития событий и достижения определенной цели. Неспособность к эффективному долгосрочному планированию ограничивает применение БЯМ в различных областях, таких как робототехника, автономное управление и разработка интеллектуальных агентов.
Для успешного функционирования в сложных средах требуется развитое “долгосрочное понимание” — способность предвидеть последствия действий на протяжении длительной последовательности шагов. Стандартные архитектуры больших языковых моделей (LLM) зачастую испытывают трудности с формированием подобного понимания, поскольку они ориентированы на обработку ближайшего контекста и испытывают сложности с поддержанием последовательности мыслей на большом временном горизонте. Это ограничение проявляется в неспособности эффективно планировать сложные задачи, требующие нескольких этапов, и в склонности к ошибкам при принятии решений, последствия которых проявятся лишь спустя время. В результате, LLM испытывают трудности с задачами, требующими стратегического мышления и долгосрочного прогнозирования, что препятствует их эффективному применению в динамичных и непредсказуемых условиях реального мира.
Ограниченность в понимании долгосрочных последствий действий существенно затрудняет внедрение LLM-агентов в практические приложения, требующие развернутого взаимодействия. В сценариях, где необходимо последовательное принятие решений на протяжении длительного времени — например, в управлении сложными системами, планировании логистики или ведении переговоров — стандартные языковые модели часто демонстрируют неустойчивость и неспособность адаптироваться к изменяющимся обстоятельствам. Отсутствие способности предвидеть отдаленные последствия своих действий приводит к ошибкам, неоптимальным решениям и, как следствие, к снижению эффективности работы агента в реальных условиях. Таким образом, преодоление этой проблемы является ключевым фактором для расширения возможностей LLM и их успешного применения в широком спектре задач, требующих интеллектуального планирования и адаптации.
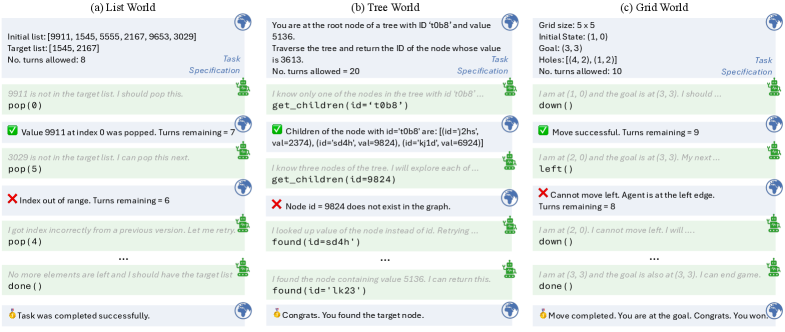
Усиление Агентов Внешними Оракулами
Для оценки влияния отдельных навыков на производительность агентов используется методология «Oracle Intervention», представляющая собой контрфактический подход. Суть заключается в предоставлении LLM-агентам дополнительной информации в критические моменты выполнения задачи, что позволяет оценить, как улучшение конкретного навыка (например, отслеживание состояния или планирование) повлияло бы на конечный результат. Этот метод позволяет изолировать вклад отдельных навыков, сравнивая производительность агента с и без «оракула», предоставляющего точные данные или рекомендации. Таким образом, «Oracle Intervention» дает возможность количественно оценить потенциальное улучшение производительности агента за счет совершенствования конкретных его способностей.
В рамках улучшения производительности LLM-агентов используется предоставление дополнительной информации в критические моменты выполнения задачи. Это включает в себя точное отслеживание состояния (state tracking), позволяющее агенту всегда иметь актуальную информацию о текущей ситуации, и поддержку планирования задач, направленную на оптимизацию последовательности действий для достижения цели. Предоставление таких данных позволяет агенту избегать ошибок, связанных с неполной или устаревшей информацией, а также более эффективно использовать свои ресурсы для решения поставленной задачи.
Для целенаправленной поддержки агентов используются конкретные типы вмешательств, включая «Вмешательство по отслеживанию состояния», «Вмешательство в планирование» и «Вмешательство по обрезке истории». «Вмешательство по отслеживанию состояния» предоставляет агенту точную информацию о текущем состоянии среды, устраняя ошибки, связанные с неполным или неверным восприятием. «Вмешательство в планирование» предоставляет агенту оптимизированные или более эффективные планы действий, улучшая процесс принятия решений. «Вмешательство по обрезке истории» ограничивает объем информации о предыдущих взаимодействиях, доступной агенту, что позволяет снизить когнитивную нагрузку и улучшить фокусировку на текущей задаче.
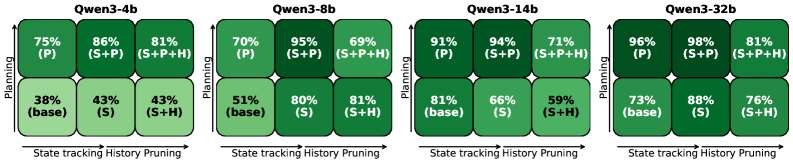
Оценка Производительности в Сложных Средах
Эффективность предложенных вмешательств оценивалась в рамках трех процедурно-генерируемых сред: ‘ListWorld’, ‘TreeWorld’ и ‘GridWorld’. ‘ListWorld’ представляет собой среду, требующую манипулирования списками данных, ‘TreeWorld’ — навигацию и взаимодействие с древовидной структурой, а ‘GridWorld’ — решение задач в двумерной сетке. Использование процедурной генерации обеспечивает неограниченное количество уникальных сценариев в каждой среде, что позволяет более надежно оценить обобщающую способность агентов и избежать переобучения на фиксированном наборе задач. Каждая среда характеризуется различной сложностью и специфическими требованиями к планированию и выполнению действий, что позволяет комплексно оценить эффективность предложенных методов в различных условиях.
Для оценки эффективности разработанных интервенций, агенты на базе языковой модели Qwen3 были протестированы в средах ListWorld, TreeWorld и GridWorld. В процессе тестирования использовалось кодирование YaRN, позволяющее расширить контекстное окно модели и улучшить обработку длинных последовательностей данных. Это позволило агентам более эффективно взаимодействовать со сложными процедурными окружениями и выполнять поставленные задачи, требующие учета информации из более широкого контекста.
Для количественной оценки влияния предложенных вмешательств на производительность агентов, использовались метрики “Точность шага” (Step Accuracy) и “Процент успешных завершений” (Success Rate). Анализ показал, что “Процент успешных завершений” существенно различался в зависимости от сложности среды (ListWorld, TreeWorld, GridWorld) и размера используемой модели (Qwen3), в то время как “Точность шага” часто оставалась на более высоком уровне. Это указывает на то, что даже незначительные ошибки на отдельных шагах могут накапливаться в процессе выполнения задачи и приводить к снижению общего процента успешных завершений.
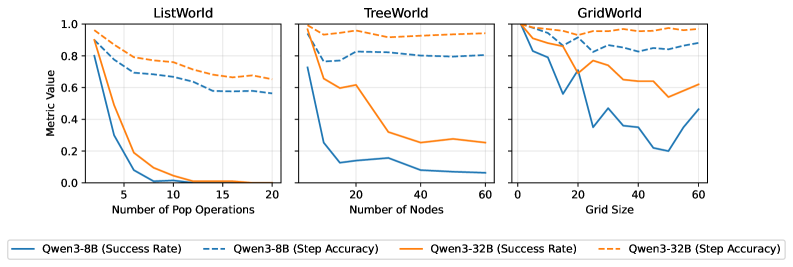
Влияние на Надежность и Эффективность ИИ-Агентов
Исследования показали, что целенаправленные вмешательства способны эффективно компенсировать врожденные ограничения в логических способностях агентов на базе больших языковых моделей (LLM). Эти вмешательства, разработанные для усиления определенных когнитивных функций, позволяют агентам более успешно справляться со сложными задачами, требующими дедуктивного мышления и планирования. В частности, было обнаружено, что, несмотря на впечатляющие возможности LLM в генерации текста, им часто не хватает последовательности в рассуждениях и способности к долгосрочному планированию. Разработанные вмешательства, направленные на улучшение этих аспектов, демонстрируют значительное повышение производительности агентов в различных сценариях, приближая их к решению задач, требующих более глубокого и надежного интеллектуального анализа.
Исследования показали, что применение методики “ReAct Prompting” в сочетании с разработанными вмешательствами значительно расширяет возможности агентов на основе больших языковых моделей (LLM) в решении сложных задач. Данный подход позволяет агентам не только генерировать ответы, но и рассуждать, планировать действия и адаптироваться к изменяющимся условиям, что принципиально отличает его от традиционных LLM. “ReAct Prompting” стимулирует агента к последовательному выполнению операций — размышления (Reason) и действия (Act) — формируя своего рода замкнутый цикл, повышающий эффективность решения задач, требующих длительного планирования и последовательных действий. Результаты демонстрируют, что сочетание этой методики с целенаправленными улучшениями способностей агента открывает путь к созданию более надежных и эффективных систем искусственного интеллекта, способных успешно функционировать в реальных условиях.
Исследования показали, что эффективность различных методов улучшения работы языковых моделей (LLM) существенно различается в зависимости от их размера. В частности, техника «обрезки истории» — удаление устаревшей информации из контекста — оказалась полезной для небольших моделей, позволяя им более эффективно обрабатывать информацию и избегать перегрузки. Однако, для крупных моделей, применение этой же техники привело к снижению производительности, указывая на то, что крупные модели способны более эффективно управлять большим объемом контекстной информации. Данный факт подчеркивает важность разработки индивидуальных стратегий улучшения навыков LLM, адаптированных к их конкретным особенностям и архитектуре. Такой подход открывает перспективы для создания более надежных и эффективных AI-агентов, способных решать сложные задачи, требующие длительного планирования и последовательного принятия решений в реальных условиях.
Исследование, представленное в данной работе, фокусируется на выявлении узких мест в навыках агентов, работающих в многошаговых взаимодействиях. Авторы предлагают методологию с использованием внешних вмешательств и процедурно-генерируемых сред для изолированного анализа влияния планирования, отслеживания состояния и обрезки истории. Этот подход позволяет более точно определить, какие аспекты системы нуждаются в улучшении для достижения стабильной работы в долгосрочной перспективе. Как заметил Андрей Колмогоров: «Вероятность события может быть оценена по частоте, с которой оно происходит в длительной серии испытаний». Эта мысль перекликается с идеей о необходимости длительного тестирования и анализа систем для выявления закономерностей и слабых мест, что особенно важно при разработке сложных агентов, способных к долгосрочному планированию и адаптации.
Что дальше?
Представленная работа, исследуя узкие места в планировании многооборотными агентами, лишь подчеркивает неизбежность деградации любой сложной системы. Ограничения, выявленные в отслеживании состояния и управлении историей, — это не столько технические проблемы, сколько проявления энтропии, естественного процесса «эрозии» когнитивной инфраструктуры. Разделение навыков и искусственное создание процедурно-генерируемых сред — полезные инструменты, но они лишь отсрочивают неизбежное — необходимость поиска более устойчивых архитектур, способных противостоять течению времени.
Акцент на «оракулах» — внешних источниках информации — вызывает определенную иронию. Вмешательство «божественной» помощи, хотя и улучшает краткосрочные результаты, не решает фундаментальную проблему самодостаточности агента. Более перспективным представляется не столько стремление к абсолютной точности, сколько разработка механизмов адаптации и самокоррекции, позволяющих агенту достойно функционировать в условиях неполноты и неопределенности.
Будущие исследования, вероятно, сосредоточатся на разработке более компактных и эффективных представлений состояния, а также на алгоритмах, способных эффективно извлекать знания из ограниченного объема исторических данных. Однако, истинный прогресс, возможно, потребует смещения парадигмы — от попыток построить идеального агента к созданию систем, способных к эволюции и обучению на протяжении длительного времени, подобно тем, что выдерживают испытание временем.
Оригинал статьи: https://arxiv.org/pdf/2601.16649.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS/USD
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-01-27 04:06