Автор: Денис Аветисян
Исследователи предложили оптимизированную архитектуру Decision Transformer, избавляющуюся от избыточной зависимости от полной истории наград для повышения эффективности и скорости обучения.
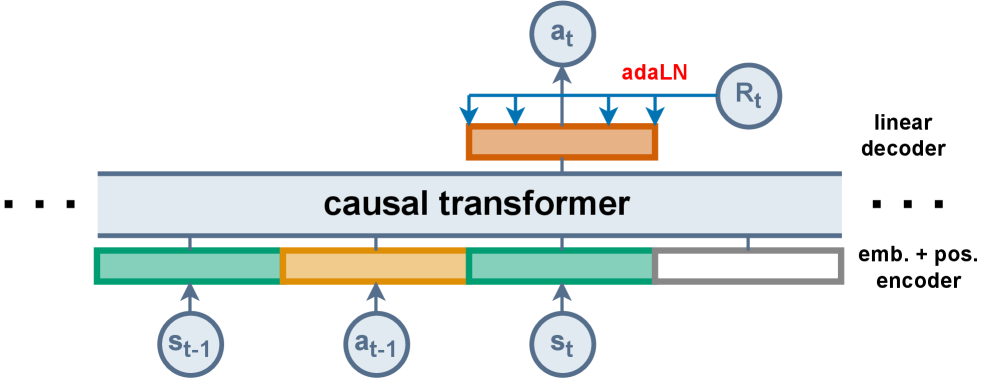
Предложенная модель Decoupled DT (DDT) обуславливает поведение агента только текущей наградой, что позволяет снизить вычислительную сложность и улучшить производительность в задачах обучения с подкреплением.
Несмотря на успехи в обучении с подкреплением на основе данных, архитектура Decision Transformer (DT) содержит избыточность в использовании Return-to-Go (RTG). В работе ‘Decoupling Return-to-Go for Efficient Decision Transformer’ авторы выявляют, что полное последовательное представление RTG для предсказания действий является излишним, поскольку ключевую роль играет лишь текущее значение. Предложенная Decoupled DT (DDT) упрощает архитектуру, обрабатывая только последовательности наблюдений и действий, что повышает производительность и снижает вычислительные затраты. Сможет ли данный подход стать основой для создания более эффективных и масштабируемых алгоритмов обучения с подкреплением на основе данных?
За пределами проб и ошибок: Ограничения традиционного обучения с подкреплением
Традиционно, обучение с подкреплением требует значительного количества взаимодействий со средой для выработки оптимальной стратегии. Этот подход, хоть и эффективный в контролируемых условиях, становится проблематичным применительно к реальным задачам. Представьте себе робота, обучающегося ходить: для достижения стабильного результата потребуется бесчисленное количество попыток и падений. Аналогично, в сложных системах, таких как автономное вождение или управление финансовыми рынками, каждое взаимодействие может быть дорогостоящим, небезопасным или попросту невозможным. Ограниченность ресурсов, высокие затраты на эксперименты и необходимость избегать рискованных ситуаций делают классическое обучение с подкреплением непрактичным для многих перспективных приложений, побуждая исследователей к поиску альтернативных подходов, минимизирующих потребность в прямом взаимодействии со средой.
Несмотря на свою теоретическую элегантность, динамическое программирование сталкивается с серьезными ограничениями при решении задач в сложных, реальных сценариях. Суть проблемы заключается в так называемом «проклятии размерности» — экспоненциальном росте вычислительной сложности и объема памяти, необходимого для хранения и обработки информации о всех возможных состояниях и действиях. По мере увеличения количества переменных и параметров, описывающих систему, пространство состояний растет настолько быстро, что становится практически невозможным перебрать все варианты и найти оптимальное решение. O(s^n), где s — количество состояний, а n — количество переменных, демонстрирует эту экспоненциальную зависимость. В результате, даже при наличии полной модели окружающей среды, динамическое программирование становится непрактичным инструментом для решения задач, характерных для современной робототехники, управления сложными системами или анализа больших объемов данных.
Зависимость от непосредственного взаимодействия со средой и проблемы масштабируемости существенно ограничивают применение обучения с подкреплением в областях, где получение данных затруднено или связано с высокими затратами. В ситуациях, когда эксперименты в реальном времени невозможны или слишком дороги — например, в робототехнике с дорогостоящим оборудованием, медицине или финансах — традиционные алгоритмы обучения с подкреплением демонстрируют низкую эффективность. Ограниченное количество проб и ошибок препятствует эффективной оптимизации стратегий, а экспоненциальный рост вычислительной сложности с увеличением размерности пространства состояний делает решение задачи практически невозможным. Таким образом, необходимость разработки методов, способных обучаться на ограниченных данных и масштабироваться для решения сложных задач, становится критически важной для расширения сферы применения обучения с подкреплением.
Последовательное моделирование как парадигмальный сдвиг в обучении с подкреплением
Обучение с подкреплением в автономном режиме (offline reinforcement learning) использует предварительно собранные наборы данных, что позволяет обойти необходимость во взаимодействии со средой в процессе обучения. Это означает, что агент обучается на статических данных, собранных ранее другими агентами или экспертами, вместо того, чтобы активно исследовать среду и собирать данные самостоятельно. Такой подход особенно полезен в ситуациях, где взаимодействие со средой дорогостоящее, рискованное или попросту невозможно, например, в робототехнике, здравоохранении или финансах. Использование исторических данных позволяет агенту извлекать знания из существующих траекторий и применять их для принятия оптимальных решений в новых ситуациях, не требуя онлайн-взаимодействия.
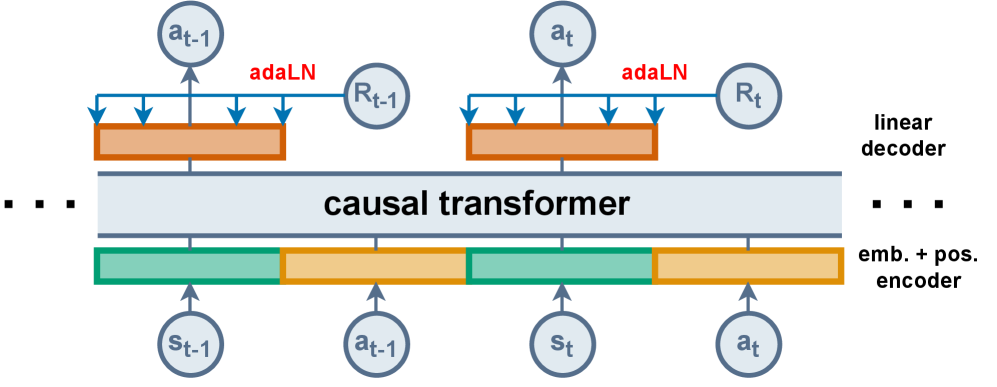
Трансформер принятия решений (Decision Transformer) представляет собой подход к обучению с подкреплением, который переформулирует задачу как проблему моделирования последовательностей. Вместо традиционного определения политики и функции ценности, он рассматривает траектории как упорядоченные последовательности состояний, действий и вознаграждений. Каждая траектория представляется как единая последовательность токенов, где каждый токен кодирует информацию о состоянии, предпринятом действии и полученном вознаграждении. Это позволяет применять архитектуру Transformer, изначально разработанную для обработки естественного языка, к задачам обучения с подкреплением, что потенциально позволяет моделировать сложные зависимости в последовательных данных и предсказывать оптимальные действия на основе исторических траекторий.
Использование архитектуры Transformer в задачах моделирования последовательностей предоставляет значительные возможности для выявления сложных взаимосвязей в последовательных данных. Transformer, изначально разработанный для обработки естественного языка, эффективно улавливает долгосрочные зависимости благодаря механизму внимания (attention), позволяющему взвешивать вклад различных элементов последовательности при прогнозировании последующих. В контексте обучения с подкреплением, это позволяет моделировать не только непосредственные последствия действий, но и учитывать влияние действий, предпринятых на более ранних этапах траектории, что критически важно для решения задач с отложенным вознаграждением и сложной динамикой. Способность Transformer к параллельной обработке данных также обеспечивает повышение эффективности обучения по сравнению с рекуррентными нейронными сетями.
Обусловленность для управления: Направляя Трансформер принятия решений
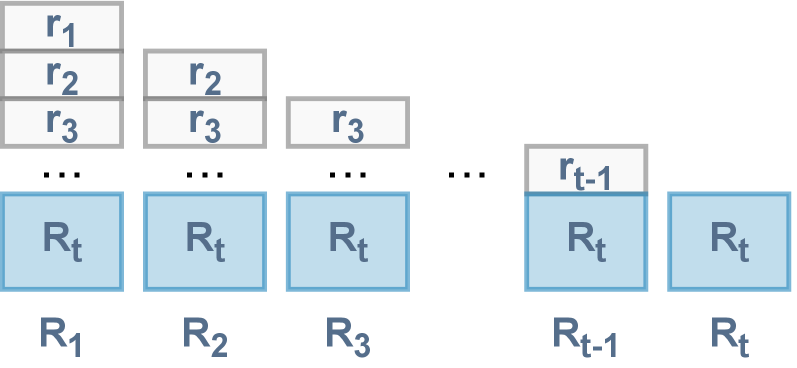
Трансформер принятия решений (Decision Transformer) использует сигнал Return-to-Go (RTG) в качестве условия, позволяя политике предсказывать будущие кумулятивные награды. RTG представляет собой ожидаемую сумму наград, которую агент получит, начиная с текущего состояния и до конца эпизода. Вместо прогнозирования действий напрямую, модель обучается предсказывать последовательность действий, которые максимизируют RTG. Это позволяет модели планировать и выбирать действия, ориентируясь на долгосрочные цели и потенциальные будущие награды, что является ключевым отличием от традиционных методов обучения с подкреплением.
Методы, такие как Hindsight Information Matching (HIM) и Reward Conditioned Supervised Learning (RCSL), позволяют модели Decision Transformer (DT) более эффективно извлекать информацию из неоптимальных траекторий. HIM предполагает переоценку награды в моменте, как если бы агент действовал оптимально для достижения определенного результата, даже если это не так. RCSL, в свою очередь, обучает модель предсказывать действия, основываясь на полученной награде и Return-to-Go (RTG), что позволяет ей лучше понимать, какие действия привели к определенным результатам, даже если эти результаты не являются оптимальными. В результате, использование HIM и RCSL позволяет DT обучаться на более широком спектре данных, включая данные, полученные в процессе исследования или при неоптимальных действиях агента, что повышает его общую производительность и надежность.
Декуплированная Трансформерная Политика (DDT) упрощает процесс обуславливания, фокусируясь исключительно на величине Return-to-Go (RTG), что позволяет повысить эффективность и производительность модели. В ходе экспериментов на наборе данных D4RL, DDT продемонстрировала приблизительно на 10% лучшие результаты по сравнению с оригинальной Трансформерной Политикой (DT). Упрощение обуславливания за счет исключения дополнительных сигналов позволило снизить вычислительную сложность и улучшить способность модели к обобщению, что положительно сказалось на итоговой производительности.
Решение проблемы смещения распределения и безопасности политики
Алгоритмы, такие как CQL, IQL и BCQ, используют методы регуляризации ценности и ограничения политики для предотвращения отклонения изученной политики от поведения, демонстрируемого исходной политикой. Данный подход направлен на снижение рисков, связанных с экстраполяцией на ранее не встречавшиеся состояния и действия, что особенно важно в задачах обучения с подкреплением вне сети. Регуляризация ценности ограничивает оценки ценностей, предотвращая переоценку действий, которые не были представлены в наборе данных. Ограничения политики, в свою очередь, непосредственно ограничивают действия, которые может предпринимать изученная политика, удерживая ее в пределах разумного диапазона, заданного поведением, наблюдаемым в данных. В результате, эти алгоритмы стремятся к более безопасной и надежной работе, избегая непредсказуемого поведения в новых ситуациях и обеспечивая более стабильное обучение даже при ограниченном количестве данных.
Методы, такие как CQL, IQL и BCQ, направлены на смягчение рисков, связанных с экстраполяцией поведения агента на ранее не встречавшиеся состояния и действия. Обучение с подкреплением часто сталкивается с проблемой непредсказуемости в новых ситуациях, когда агент вынужден действовать в условиях, отличных от тех, на которых он обучался. Использование регуляризации значений и ограничений на политику позволяет удержать политику агента вблизи поведения, наблюдаемого в обучающих данных, что значительно повышает безопасность и надежность его работы. В результате, агент с большей вероятностью будет действовать предсказуемо и эффективно даже в незнакомых окружениях, избегая потенциально опасных или нежелательных действий, которые могли бы возникнуть при неконтролируемой экстраполяции.
Оценка эффективности разработанных алгоритмов, таких как CQL, IQL и BCQ, проводилась на стандартных бенчмарках D4RL, что позволило подтвердить их способность успешно решать задачи обучения с подкреплением в офлайн-режиме. Особого внимания заслуживает алгоритм DDT, который не только достиг улучшенных результатов, но и существенно сократил требуемую длину входной последовательности. Это стало возможным благодаря использованию квадратичной зависимости вычислительных затрат Transformer от длины последовательности, позволив уменьшить её с 3000 до 2000 единиц. Такое снижение длины последовательности открывает возможности для более эффективного обучения и применения алгоритмов в условиях ограниченных вычислительных ресурсов и при работе с большими объемами данных.
Исследование демонстрирует, что избыточность в архитектуре Decision Transformer, связанная с полным историческим контекстом Reward-to-Go, является предсказуемой слабостью. Авторы, словно пророки, читающие логи машинного обучения, выявили эту закономерность и предложили Decoupled DT, как средство смягчения последствий. В этом кроется глубокая истина: надежда на идеальную архитектуру — это форма отрицания энтропии, поскольку любая сложная система неминуемо содержит в себе семена будущего сбоя. Упрощение модели, отказ от избыточного контекста — это не просто повышение эффективности, но и признание неизбежности хаоса, попытка управлять им, а не искоренить. Как заметила Ада Лавлейс: «Развитие науки требует смелости отказаться от старых представлений и принять новые». Этот принцип находит свое отражение в предложенном подходе к оптимизации Decision Transformer.
Что Дальше?
Представленная работа демонстрирует, что даже в, казалось бы, устоявшихся архитектурах, таких как Decision Transformer, кроются избыточности. Отказ от полной истории Reward-to-Go не является революцией, но подтверждает старую истину: архитектура — это способ откладывать хаос, а не его устранять. Упрощение, как правило, не ведет к упрощению проблем, а лишь переносит акцент на другие, ранее скрытые аспекты. Вопрос заключается не в том, как построить идеальную систему, а в том, как создать достаточно гибкую экосистему, способную выжить в условиях непредсказуемости.
Необходимо помнить: порядок — это кеш между двумя сбоями. Decoupled DT, безусловно, повышает эффективность, но не решает фундаментальную проблему offline reinforcement learning — экстраполяцию за пределы распределения данных. Следующим шагом видится не столько в оптимизации архитектуры, сколько в разработке методов, позволяющих оценивать и учитывать неопределенность в данных, а также в исследовании способов интеграции механизмов активного обучения для минимизации риска выхода за рамки валидной области.
Нет лучших практик, есть лишь выжившие. Успех DDT указывает на то, что будущее за системами, способными к саморегуляции и адаптации. Изучение принципов устойчивости и отказоустойчивости, заимствованных из биологических систем, может оказаться более плодотворным, чем дальнейшее стремление к созданию идеальных, но хрупких конструкций. В конечном итоге, ценность архитектуры определяется не её сложностью, а способностью предвидеть и смягчать неизбежные сбои.
Оригинал статьи: https://arxiv.org/pdf/2601.15953.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- H ПРОГНОЗ. H криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
2026-01-26 02:35