Автор: Денис Аветисян
Новая модель CARD использует диффузионные модели для последовательных рекомендаций, динамически оптимизируя процесс генерации, чтобы обеспечить более точные предсказания даже при неполных данных.
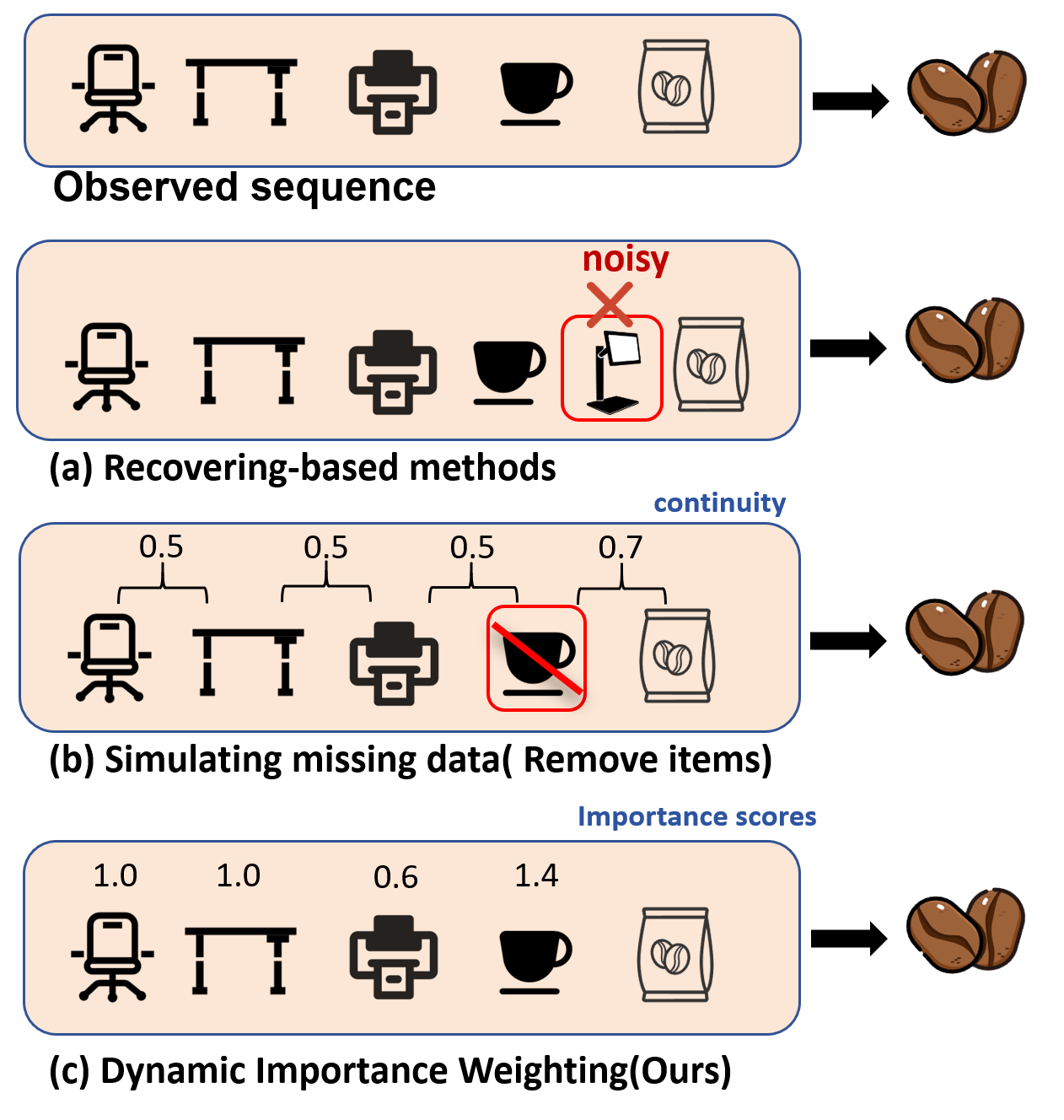
Исследование предлагает новый подход к обработке пропущенных данных в диффузионных моделях последовательных рекомендаций, основанный на контрфактическом внимании и анализе стабильности последовательностей.
Современные системы рекомендаций, переходящие к генеративным моделям на основе диффузии, часто сталкиваются с проблемой снижения качества рекомендаций из-за неполноты данных о последовательностях действий пользователей. В работе, озаглавленной ‘Enhancing guidance for missing data in diffusion-based sequential recommendation’, предложена новая модель CARD, использующая механизм внимания, основанный на контрафактах, и анализ стабильности последовательностей для динамической оптимизации сигнала управления диффузионной моделью. Этот подход позволяет эффективно обрабатывать пропущенные данные и повышать точность прогнозирования предпочтений пользователей. Сможет ли предложенный метод стать основой для создания более интеллектуальных и персонализированных систем рекомендаций в будущем?
Неполнота данных: вызов для современных рекомендательных систем
Современные системы последовательных рекомендаций играют ключевую роль в формировании персонализированного пользовательского опыта, однако их эффективность часто снижается из-за неполноты данных о взаимодействии пользователей. В реальных условиях, история действий каждого пользователя фрагментарна: не все товары просматриваются, не все покупки фиксируются, и значительная часть потенциально интересных объектов остается незамеченной системой. Эта неполнота информации представляет серьезную проблему для алгоритмов, поскольку затрудняет точное прогнозирование будущих предпочтений и, как следствие, приводит к менее релевантным и менее привлекательным рекомендациям. Отсутствие данных о прошлых взаимодействиях лишает систему возможности выявить скрытые закономерности в поведении пользователя и адаптировать рекомендации к его индивидуальным потребностям, что негативно сказывается на общей удовлетворенности и лояльности.
Традиционные методы, применяемые в последовательных рекомендательных системах, зачастую испытывают трудности при работе с неполными данными о взаимодействиях пользователей. Отсутствие информации о прошлых действиях, например, просмотренных товарах или прослушанных треках, приводит к снижению точности предсказаний и, как следствие, к ухудшению пользовательского опыта. Алгоритмы, не учитывающие пробелы в данных, могут выдавать нерелевантные рекомендации, что вызывает разочарование и снижает доверие к системе. Это особенно заметно в динамичных средах, где предпочтения пользователей быстро меняются, а игнорирование пропущенных данных усугубляет проблему неадекватных предложений и снижает общую эффективность рекомендательной системы.
Существующие методы обработки пропущенных данных в последовательных рекомендательных системах, такие как простая импутация, зачастую оказываются неспособны адекватно отразить сложную динамику поведения пользователей. Вместо того, чтобы учитывать индивидуальные паттерны взаимодействия, эти методы, как правило, заменяют отсутствующие данные средними значениями или наиболее частыми элементами, что приводит к искажению реальной картины предпочтений. В результате, рекомендации становятся менее релевантными и персонализированными, а алгоритм склонен к воспроизведению существующих предубеждений, упуская потенциально интересные для пользователя элементы. Такой подход не только снижает точность прогнозов, но и может привести к формированию замкнутого круга, когда система рекомендует только то, что уже известно о пользователе, игнорируя новые возможности и предпочтения.
Преодоление проблемы неполных данных является ключевым фактором для создания надежных и эффективных систем последовательных рекомендаций. Отсутствие информации о взаимодействии пользователей существенно снижает точность прогнозов и, как следствие, качество предоставляемого сервиса. Разработка алгоритмов, способных эффективно обрабатывать пробелы в данных и учитывать динамику поведения пользователей, позволяет не только повысить релевантность рекомендаций, но и обеспечить стабильную работу системы в условиях неполной информации. В конечном итоге, успешное решение этой задачи открывает путь к созданию персонализированных рекомендательных систем, способных адаптироваться к индивидуальным предпочтениям и обеспечивать долгосрочную удовлетворенность пользователей.
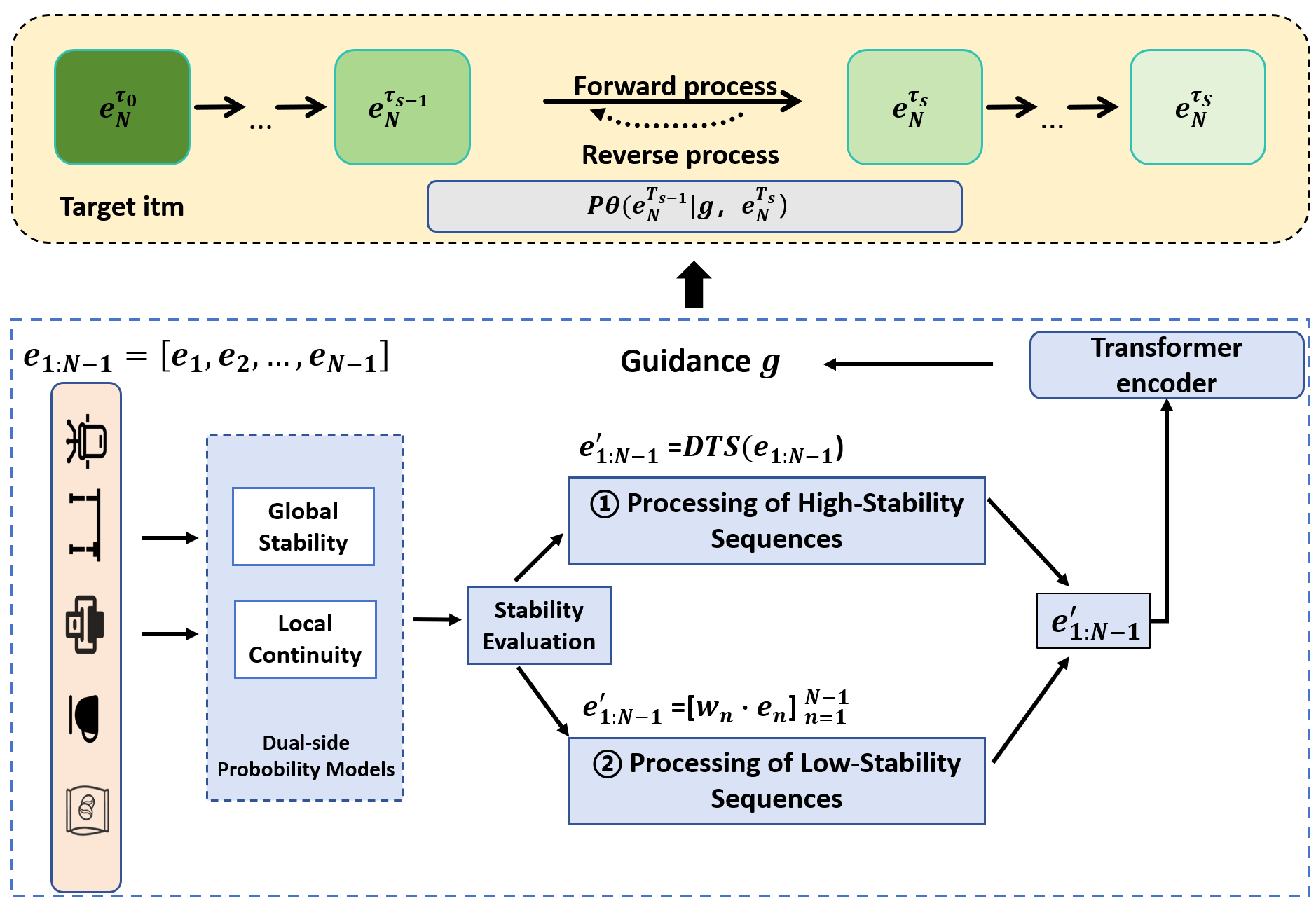
За пределами импутации: генеративные модели для восстановления последовательностей
Генеративные модели, такие как вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN), представляют собой перспективный подход к решению проблемы отсутствующих данных в последовательностях взаимодействия пользователей. В отличие от методов импутации, которые заполняют пропуски на основе статистических оценок, генеративные модели стремятся изучить базовое распределение последовательностей, моделируя вероятности различных действий пользователя. Это позволяет им не просто предсказывать наиболее вероятное следующее действие, но и генерировать правдоподобные взаимодействия, которые соответствуют изученному распределению, что потенциально повышает точность рекомендаций и качество завершенных последовательностей. Использование генеративных моделей основано на предположении, что последовательности пользователей не являются случайными, а подчиняются определенной структуре, которую можно выявить и использовать для генерации новых, реалистичных данных.
Генеративные модели, применяемые к задачам рекомендаций, позволяют восстанавливать пропущенные взаимодействия в последовательностях действий пользователей. Вместо того, чтобы просто заполнять пробелы наиболее вероятными значениями, эти модели стремятся сгенерировать правдоподобные и контекстуально релевантные действия, основываясь на изученной структуре данных. Восстановление последовательностей таким образом позволяет не только завершить информацию о пользователе, но и повысить точность предсказаний относительно будущих взаимодействий, поскольку модель учитывает более полную картину предпочтений и поведения пользователя. Это особенно важно в ситуациях, когда данные о пользователях неполны или содержат значительные пропуски, что является типичной проблемой в реальных рекомендательных системах.
Ранние реализации вариационных автоэнкодеров (VAE) и генеративно-состязательных сетей (GAN) в системах рекомендаций столкнулись с проблемами, связанными со стабильностью обучения и качеством генерируемых данных. Обучение GAN часто приводило к нестабильности из-за трудностей в балансировке между генератором и дискриминатором, что выражалось в исчезающих или взрывающихся градиентах. VAE, в свою очередь, демонстрировали тенденцию к генерации размытых или нереалистичных последовательностей, что снижало их эффективность в контексте рекомендаций. Эти недостатки были связаны с особенностями архитектур моделей, функциями потерь и сложностью моделирования длинных и сложных последовательностей взаимодействий пользователей.
Диффузионные модели, относительно недавно появившиеся в области генеративных инструментов, демонстрируют превосходные результаты в различных областях, включая обработку изображений и звука. В отличие от традиционных генеративных моделей, таких как VAE и GAN, диффузионные модели работают путем постепенного добавления шума к данным, а затем обучения модели обращать этот процесс, восстанавливая исходные данные из шума. Этот подход обеспечивает стабильность обучения и позволяет генерировать высококачественные данные, что делает их перспективными для задач последовательных рекомендаций, где необходимо предсказывать последовательности действий пользователей на основе неполных данных. Потенциал диффузионных моделей заключается в их способности улавливать сложные зависимости в данных и генерировать правдоподобные и разнообразные последовательности взаимодействий.
CARD: Контрфактическое внимание и диффузия для надежных рекомендаций
Механизм CARD представляет собой новую структуру, объединяющую диффузионные модели с механизмом контрфактического внимания для эффективной обработки пропущенных данных в задачах последовательных рекомендаций. В отличие от традиционных подходов, которые либо игнорируют пропуски, либо заполняют их простыми стратегиями, CARD использует диффузионную модель для генерации правдоподобных взаимодействий, учитывая контекст всей последовательности. Контрфактическое внимание позволяет модели оценивать влияние каждого потенциального взаимодействия на общую точность рекомендаций, эффективно фокусируясь на заполнении пропусков таким образом, чтобы максимизировать релевантность и качество рекомендаций. Данный подход позволяет не только восстанавливать пропущенные взаимодействия, но и учитывать неопределенность в данных, обеспечивая более надежные и точные рекомендации даже при наличии значительных пропусков в истории пользователя.
В основе CARD лежит использование Transformer Encoder для обработки последовательности взаимодействий пользователя. Этот энкодер преобразует входную последовательность в вектор руководства (Guidance Vector), который служит для управления процессом диффузии. Вектор руководства кодирует информацию о предыдущих взаимодействиях и используется для направления генерации последующих, правдоподобных взаимодействий. По сути, он определяет вероятностное распределение для генерации новых элементов в последовательности, позволяя модели предсказывать наиболее релевантные действия пользователя, основываясь на его истории.
В основе CARD лежит инновационный подход к оценке значимости каждого элемента последовательности взаимодействий посредством метрики «Снижение ошибки предсказания» (Prediction Error Reduction). Данная метрика количественно определяет вклад каждого элемента в повышение точности предсказания будущих взаимодействий. Алгоритм CARD использует полученные значения для приоритезации генерации элементов, которые оказывают наибольшее влияние на снижение общей ошибки предсказания, что позволяет эффективно фокусироваться на наиболее информативных взаимодействиях и повышать надежность рекомендаций, особенно в условиях неполных данных. Фактически, это позволяет модели динамически оценивать важность каждого действия пользователя в последовательности и учитывать эту важность при формировании новых рекомендаций.
Для повышения качества генерируемых последовательностей и эффективной обработки пропущенных данных, CARD использует стратегии уменьшения избыточности, такие как ‘DTS’ (Detail-preserving Transformation Strategy). Одновременно с этим, пропуски обрабатываются посредством методов симуляции пропусков, в частности, ‘TDM’ (Trajectory Data Masking). Применение ‘TDM’ регулируется принципами ‘локальной непрерывности’ и ‘глобальной стабильности’, которые обеспечивают, что сгенерированные взаимодействия соответствуют как непосредственному контексту, так и общей структуре предпочтений пользователя. Это позволяет избежать генерации неправдоподобных или противоречивых последовательностей взаимодействий.
Эмпирическая валидация и прирост производительности
В ходе всестороннего тестирования модель CARD демонстрирует стабильное превосходство над существующими методами в области рекомендательных систем. Оценка проводилась на авторитетных наборах данных, включая ‘Zhihu Dataset’ и ‘KuaiRec Dataset’, с использованием ключевых метрик, таких как ‘Hit Ratio (HR@20)’ и ‘Normalized Discounted Cumulative Gain (NDCG@20)’. Результаты показывают, что CARD не только надежно воспроизводит существующие результаты, но и значительно улучшает их, обеспечивая более точные и релевантные рекомендации для пользователей. Данная стабильность и высокая производительность подтверждают эффективность предложенного подхода и его потенциал для широкого применения в различных рекомендательных сервисах.
В основе CARD лежит механизм контрфактического внимания, позволяющий модели сосредотачиваться на генерации взаимодействий, наиболее соответствующих предпочтениям пользователя. Вместо того, чтобы просто предсказывать вероятные действия, система анализирует, какие изменения в истории взаимодействия привели бы к иным, потенциально более релевантным результатам. Такой подход позволяет выявлять скрытые интересы и предлагать рекомендации, которые пользователь, возможно, не рассматривал бы самостоятельно. Это приводит к значительному повышению точности рекомендаций, поскольку CARD не просто воспроизводит прошлые паттерны, а активно исследует альтернативные варианты, адаптируясь к индивидуальным запросам и обеспечивая более персонализированный опыт.
В основе CARD лежит диффузионный подход, обеспечивающий стабильное и высококачественное генерирование рекомендаций. В отличие от предыдущих генеративных моделей, часто сталкивающихся с проблемами нестабильности и генерации нерелевантного контента, диффузия позволяет постепенно добавлять шум к данным, а затем восстанавливать их, что обеспечивает более плавный и контролируемый процесс. Этот метод позволяет избежать резких скачков в генерации и гарантирует, что создаваемые рекомендации будут не только точными, но и соответствуют предпочтениям пользователя, минимизируя риск выдачи случайных или нежелательных результатов. Благодаря этому CARD демонстрирует повышенную надежность и качество генерируемых рекомендаций по сравнению с альтернативными решениями.
В ходе экспериментов на общедоступном наборе данных Zhihu, модель CARD продемонстрировала значительное превосходство над существующими аналогами. В частности, зафиксировано увеличение показателя Hit Ratio на 10.30% (HR@20) и Normalized Discounted Cumulative Gain на 5.06% (NDCG@20) по сравнению с наиболее эффективными базовыми моделями. Данные результаты свидетельствуют о существенном повышении точности рекомендаций, обеспечиваемом CARD, и подтверждают ее потенциал для улучшения пользовательского опыта в системах, основанных на рекомендациях контента.
«`html
Исследование, представленное в данной работе, стремится к оптимизации рекомендательных систем, работающих с неполными данными последовательностей. Авторы предлагают CARD — подход, использующий диффузионные модели и динамическую оптимизацию управляющего сигнала. Данный метод, опираясь на анализ устойчивости последовательностей и механизм внимания, позволяет преодолеть ограничения, возникающие при работе с пропущенными данными. Как однажды заметил Карл Фридрих Гаусс: «Если бы я мог, я бы избавился от всего, кроме математики». Эта фраза отражает стремление к точности и ясности, которые являются ключевыми принципами, лежащими в основе CARD, где сложный процесс рекомендаций упрощается благодаря продуманному анализу и оптимизации.
Куда Далее?
Представленная работа, стремясь к элегантности в обработке неполных данных в диффузионных моделях рекомендаций, неизбежно обнажает ещё большую сложность лежащей в основе проблемы. Оптимизация сигнала управления, безусловно, является шагом вперед, но она лишь временно откладывает вопрос о фундаментальной неопределенности, присущей любой последовательности, полученной из фрагментарных наблюдений. Попытка «стабилизировать» последовательность — это, по сути, признание ее изначально нестабильной природы.
Дальнейшие исследования, вероятно, должны сместиться от поиска все более изощренных методов «заполнения пробелов» к разработке моделей, которые признают и учитывают присущую им неполноту как неотъемлемую часть процесса рекомендации. Иными словами, необходимо стремиться не к иллюзии полного знания, а к честному представлению о том, что известно, а что — нет. Простота в признании ограничений — вот путь к подлинному пониманию.
Очевидно, что в будущем следует обратить внимание на адаптацию подходов к оценке неопределенности, не ограничиваясь статистическими метриками, а принимая во внимание когнитивные аспекты восприятия рекомендаций пользователем. Возможно, ключевым моментом станет не точность предсказания, а способность модели передать уверенность в своих рекомендациях, позволяя пользователю осознанно принимать решения.
Оригинал статьи: https://arxiv.org/pdf/2601.15673.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- H ПРОГНОЗ. H криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
2026-01-25 08:11