Автор: Денис Аветисян
Новая методика позволяет экологам создавать собственные системы анализа изображений, полученных с фотоловушек, без необходимости глубоких знаний в программировании.

Представлен гибкий и доступный конвейер машинного обучения для классификации изображений диких животных, успешно примененный для определения возраста и пола благородного оленя.
Несмотря на растущий объем данных, получаемых в экологических исследованиях, применение методов машинного обучения для анализа изображений остается сложной задачей для многих специалистов. В данной работе, ‘Beyond Off-the-Shelf Models: A Lightweight and Accessible Machine Learning Pipeline for Ecologists Working with Image Data’, представлен гибкий и доступный конвейер для создания специализированных моделей классификации изображений, продемонстрированный на примере классификации оленей по возрасту и полу с использованием данных фотоловушек. Полученные результаты, включая точность в 90.77% для определения возраста и 96.15% для определения пола, показывают возможность надежной демографической классификации даже при ограниченном объеме данных. Не откроет ли это новый путь для более широкого использования машинного обучения в мониторинге дикой природы и анализе популяций?
Эффективность мониторинга дикой природы: преодоление информационного узкого места
Эффективный мониторинг дикой природы все больше зависит от анализа огромных массивов изображений, полученных с фотоловушек, однако ручная аннотация этих данных представляет собой серьезную проблему, требующую значительных временных и финансовых затрат. Традиционные методы, основанные на визуальном просмотре каждого изображения человеком, становятся непрактичными при масштабах современных исследований, охватывающих обширные территории и длительные периоды времени. Этот трудоемкий процесс замедляет получение критически важных данных о популяциях животных, их перемещениях и поведении, что существенно затрудняет принятие своевременных и обоснованных решений в области охраны природы и управления дикими животными. Автоматизация процесса аннотации становится ключевым фактором для преодоления этого узкого места и обеспечения оперативного получения информации, необходимой для сохранения биоразнообразия.
Точное определение местоположения животных на изображениях, получаемых с фотоловушек, начинается с выделения их границ на снимках — процесса, известного как определение ограничивающих рамок. Этот этап критически важен, поскольку от него зависит корректность последующего анализа и идентификации особей. Для автоматизации этой трудоемкой задачи часто используется программа MegaDetector, способная обрабатывать огромные объемы изображений и быстро находить потенциальные объекты. MegaDetector, анализируя визуальные признаки, помогает существенно ускорить процесс обработки данных, позволяя исследователям сосредоточиться на более сложных задачах, таких как определение вида животного и его индивидуальные характеристики, что в конечном итоге способствует более эффективному мониторингу дикой природы и её сохранению.
Современные методы мониторинга дикой природы сталкиваются с серьезными трудностями, обусловленными огромным объемом получаемых данных. Обработка тысяч изображений, поступающих с автоматических фотоловушек, требует значительных временных и финансовых затрат, что замедляет получение критически важных сведений о популяциях животных. Эта задержка в анализе информации препятствует своевременному реагированию на изменения в численности, миграциях и состоянии здоровья популяций, снижая эффективность природоохранных мероприятий и ставя под угрозу долгосрочное сохранение биоразнообразия. Неспособность оперативно извлекать полезные данные из этих массивов информации существенно ограничивает возможности ученых и специалистов по охране природы в принятии обоснованных решений.
Автоматизированный конвейер классификации: математическая элегантность в действии
Автоматизированный конвейер классификации объединяет алгоритмы обнаружения ограничивающих рамок (bounding box detection) с моделями глубокого обучения для автоматической идентификации и классификации животных. Данный подход позволяет сначала локализовать животное на изображении, определяя его местоположение посредством ограничивающей рамки, а затем использовать модель глубокого обучения для определения вида животного на основе изображения внутри этой рамки. Интеграция этих двух этапов обеспечивает более точную и надежную классификацию по сравнению с использованием только моделей классификации изображений, поскольку позволяет модели сосредоточиться на релевантной области изображения, содержащей животное.
В основе нашей системы классификации лежат предварительно обученные сверточные нейронные сети, такие как ResNet50, VGG19, DenseNet161 и DenseNet201. Использование предварительно обученных моделей позволяет значительно сократить время обучения и повысить точность классификации благодаря переносу знаний, полученных на больших наборах данных, таких как ImageNet. Выбор конкретной архитектуры зависит от компромисса между скоростью вычислений и требуемой точностью: ResNet50 обеспечивает баланс, VGG19 отличается простотой структуры, а DenseNet161 и DenseNet201, благодаря более глубокой структуре и соединениям, позволяют достичь более высокой точности, но требуют больших вычислительных ресурсов.
Для повышения устойчивости и обобщающей способности модели, особенно при ограниченном объеме обучающих данных, в конвейере используются методы увеличения данных (Data Augmentation). Данные техники включают в себя случайные преобразования изображений, такие как повороты, масштабирование, сдвиги, изменения яркости и контрастности, а также горизонтальные отражения. Эти преобразования позволяют искусственно расширить обучающую выборку, представляя модели больше вариаций существующих данных и снижая риск переобучения. Применение Data Augmentation способствует улучшению способности модели корректно классифицировать объекты на изображениях, не встречавшихся в исходном наборе данных.
Конфигурационный файл в формате TOML используется в конвейере классификации для обеспечения воспроизводимости результатов и упрощения экспериментов с различными архитектурами моделей и гиперпараметрами. Этот файл позволяет четко определить все параметры, необходимые для обучения и оценки моделей, включая пути к данным, параметры оптимизации, архитектуру нейронной сети (например, выбор между ResNet50, VGG19 и другими) и параметры аугментации данных. Сохранение этих параметров в структурированном файле TOML гарантирует, что эксперименты можно будет точно воспроизвести в будущем, а также позволяет легко изменять и тестировать различные конфигурации без изменения кода конвейера. Использование TOML обеспечивает читаемость и простоту редактирования конфигурации, что ускоряет процесс разработки и оптимизации моделей.
Демографический анализ: классификация по возрасту и полу с высокой точностью
Разработанный конвейер обеспечивает классификацию особей косули европейской (Capreolus capreolus) по возрастным группам и полу, предоставляя важные демографические данные для мониторинга популяции. Классификация по возрасту позволяет выделять молодые, взрослые и старые особи, а классификация по полу — определять самцов и самок. Полученные данные являются основой для оценки численности, структуры популяции и динамики её изменений, что необходимо для эффективного управления и сохранения вида. Точность классификации по возрасту составляет 90.68%, с точностью (precision) 82.22%, полнотой (recall) 90.68% и F1-оценкой 86.24%, в то время как точность классификации по полу достигает 92.53%, с точностью 92.79%, полнотой 92.53% и F1-оценкой 91.96%.
Для обеспечения достоверности результатов классификации оленей, в конвейере используются пороговые значения достоверности (Confidence Threshold) и неопределенности (Uncertainty Threshold). Эти пороги применяются к вероятностным оценкам, выдаваемым моделью, для отсеивания предсказаний с низкой степенью уверенности. Предсказания, у которых вероятность наиболее вероятного класса ниже установленного порога достоверности, или разница между вероятностями наиболее и второго по вероятности классов ниже порога неопределенности, исключаются из финального набора данных. Такой подход позволяет минимизировать количество ложных срабатываний и повысить общую надежность полученных демографических данных.
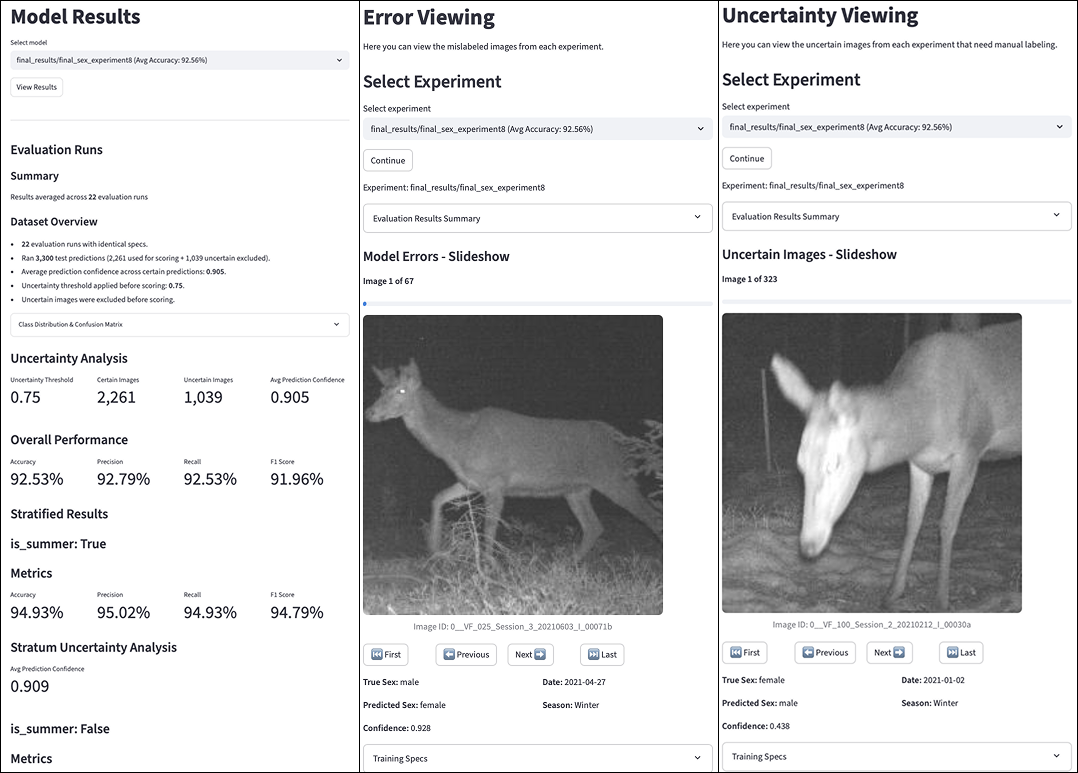
Интерфейс Streamlit предоставляет удобную платформу для анализа результатов классификации оленей. Пользователи могут визуально просматривать предсказания модели по категориям возраста и пола, что позволяет проводить детальный анализ ошибок. Функционал интерфейса включает инструменты для сравнения производительности различных моделей классификации, позволяя оценить влияние различных параметров и алгоритмов на точность предсказаний. Возможность интерактивной проверки предсказаний облегчает выявление систематических ошибок и улучшение общей надежности системы классификации.
Результаты классификации оленей благородного происхождения демонстрируют высокую точность определения возраста и пола. Точность классификации по возрасту составила 90.68%, при этом достигнуты следующие показатели: точность (precision) — 82.22%, полнота (recall) — 90.68%, и F1-мера — 86.24%. Для классификации по полу были получены следующие результаты: точность — 92.79%, полнота — 92.53%, и F1-мера — 91.96%. Высокая точность этих классификаций позволяет использовать полученные данные для более эффективного управления популяциями и разработки стратегий сохранения вида.
Оптимизация аннотации данных: активное обучение как инструмент повышения эффективности
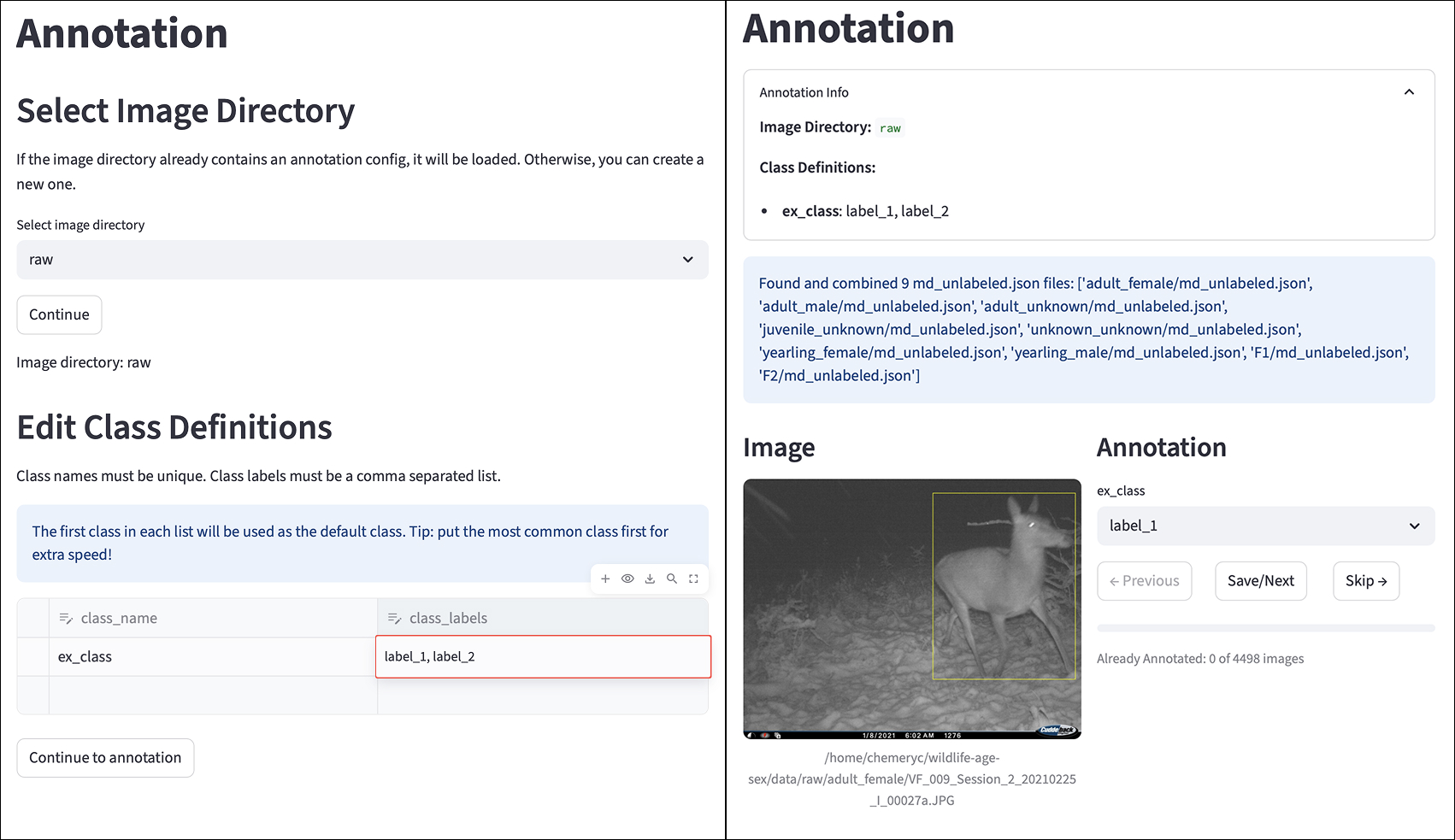
Для снижения затрат на разметку данных и повышения эффективности моделей была внедрена система активного обучения. Эта система представляет собой последовательность действий, направленных на интеллектуальный отбор наиболее информативных изображений для ручной аннотации. Вместо случайного выбора, система автоматически определяет те образцы, в которых модель проявляет наибольшую неуверенность, тем самым концентрируя усилия разметчиков на тех данных, которые принесут наибольшую пользу для обучения. Такой подход позволяет значительно сократить объем необходимой ручной работы, одновременно повышая точность и обобщающую способность итоговой модели, что особенно важно при работе с большими объемами данных.
В рамках разработанной системы активного обучения, процесс аннотирования данных оптимизируется за счет целенаправленного отбора наиболее информативных изображений. Вместо случайной выборки, алгоритм автоматически определяет те изображения, в отношении которых модель демонстрирует наибольшую неуверенность в своих предсказаниях. Такой подход позволяет сосредоточить усилия аннотаторов на тех данных, которые наиболее существенно повлияют на повышение точности модели, что значительно сокращает объем необходимой ручной разметки и повышает эффективность обучения. Приоритезация неопределенных изображений обеспечивает более быстрое улучшение характеристик модели по сравнению со случайным выбором данных для аннотирования.
В рамках активно обучающейся системы была внедрена концепция “экспертов по конкретным задачам”, что позволило существенно повысить точность классификации животных. Вместо использования универсальной модели, система задействует специализированные алгоритмы, обученные распознавать признаки, характерные для определенных видов или групп животных. Такой подход позволяет учитывать тонкие нюансы, которые могут быть упущены общей моделью, особенно в сложных случаях, когда изображения низкого качества или животные находятся в необычных позах. Использование экспертов по задачам не только повышает общую точность, но и позволяет более эффективно использовать ограниченные ресурсы для аннотации, фокусируясь на изображениях, где специализированные алгоритмы наиболее нуждаются в помощи человека.
Внедрение стратегии активного обучения позволило существенно сократить объем ручной разметки данных, что привело к повышению эффективности процесса обучения моделей. Вместо того, чтобы размечать весь набор данных, система самостоятельно определяет наиболее информативные изображения, требующие внимания экспертов. Этот подход не только экономит время и ресурсы, но и позволяет модели быстрее достигать высокой точности классификации, поскольку обучение фокусируется на примерах, которые действительно необходимы для улучшения её работы. Таким образом, оптимизация разметки посредством активного обучения становится ключевым фактором в создании эффективных и экономичных систем машинного зрения.
Данная работа демонстрирует стремление к созданию не просто работающих, но и математически обоснованных решений в области классификации изображений. Подход, описанный в статье, акцентирует внимание на адаптации моделей к специфическим задачам мониторинга дикой природы, что соответствует принципам минимизации избыточности и повышения точности. Как однажды заметил Джеффри Хинтон: «Иногда, чтобы сделать что-то простое, нужно приложить много усилий». Это особенно верно в контексте активного обучения и трансферного обучения, где тщательный отбор данных и адаптация моделей позволяют достичь оптимальных результатов, избегая перегруженности и необоснованной сложности. Статья подчеркивает, что элегантность решения проявляется в его способности эффективно решать поставленную задачу, а не в использовании самых современных, но неподходящих инструментов.
Куда двигаться дальше?
Представленная работа, безусловно, демонстрирует работоспособность предложенного подхода к классификации изображений, полученных с фотоловушек. Однако, стоит признать, что сама по себе «работоспособность» — это лишь отправная точка. Истинная проверка — это доказательство устойчивости и обобщающей способности, а не просто успешная работа на ограниченном наборе тестовых данных. Необходимо подвергнуть алгоритм более строгим испытаниям, используя данные, полученные в различных географических условиях и с камер, обладающих различным качеством изображения.
Особое внимание следует уделить вопросам формального анализа ошибок. Простое увеличение точности классификации не является самоцелью. Гораздо важнее понять природу этих ошибок, выявить систематические отклонения и разработать методы их устранения. Следует стремиться не к «черному ящику», дающему результат, а к прозрачному алгоритму, логика работы которого понятна и предсказуема. В противном случае, мы рискуем получить иллюзию контроля над ситуацией.
В конечном итоге, перспективы развития данного направления лежат в плоскости формализации знаний об экологии и поведении животных. Необходимо выйти за рамки простой классификации «возраст» и «пол», и перейти к построению моделей, способных делать более сложные выводы о динамике популяций и взаимодействии видов. И лишь тогда, возможно, удастся приблизиться к истинному пониманию сложных процессов, происходящих в природе.
Оригинал статьи: https://arxiv.org/pdf/2601.15813.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- H ПРОГНОЗ. H криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
2026-01-24 08:44