Автор: Денис Аветисян
Исследователи обнаружили способ восстановления конфиденциальных данных из обновлений моделей, используемых в федеративном обучении, используя генеративные модели и метод сопоставления потоков.
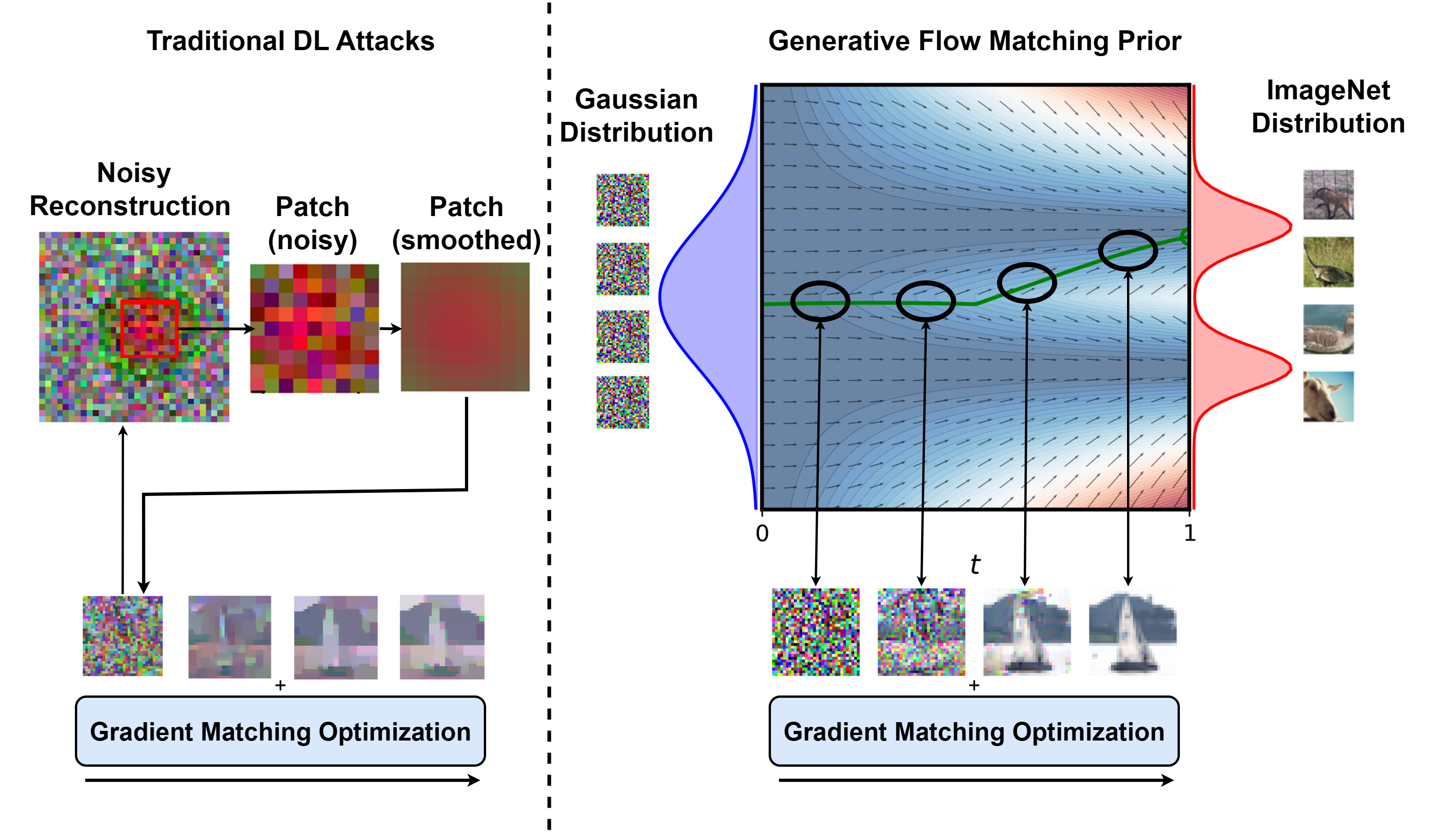
В статье представлен новый глубокий метод утечки данных, основанный на сопоставлении потоков, который демонстрирует превосходство над существующими атаками и устойчивость к защитным механизмам в сценариях федеративного обучения.
Несмотря на широкое распространение федеративного обучения как метода децентрализованной тренировки моделей, оно остается уязвимым к атакам глубокой утечки данных. В работе ‘Deep Leakage with Generative Flow Matching Denoiser’ предложен новый подход к реализации подобных атак, использующий генеративные модели на основе Flow Matching для реконструкции приватных данных из обновлений моделей. Эксперименты показали, что предложенный метод превосходит существующие аналоги по точности восстановления данных и устойчивости к различным защитным механизмам, таким как добавление шума и разрежение. Не потребуются ли новые стратегии защиты, учитывающие возможности злоумышленников, использующих мощные генеративные модели для извлечения конфиденциальной информации?
Конфиденциальность против точности: дилемма федеративного обучения
Федеративное обучение представляет собой перспективный подход к машинному обучению, позволяющий сохранять конфиденциальность данных. В отличие от традиционных методов, требующих централизованного сбора данных, федеративное обучение позволяет обучать модели непосредственно на устройствах пользователей, обмениваясь лишь параметрами модели, а не самими данными. Однако, несмотря на эту защиту, системы федеративного обучения уязвимы к утечкам информации. Анализ обновлений модели, передаваемых участниками, может раскрыть конфиденциальные сведения о данных, использованных для обучения. Это происходит из-за того, что даже незначительные изменения в параметрах модели могут содержать информацию о характеристиках исходных данных, что делает необходимым разработку и внедрение дополнительных механизмов защиты, способных противостоять сложным атакам и обеспечивать надежную конфиденциальность.
Традиционные методы федеративного обучения часто сталкиваются с проблемой баланса между точностью модели и надежными гарантиями конфиденциальности. Усиление защиты данных пользователей, как правило, приводит к снижению точности и обобщающей способности модели, поскольку добавление шума или ограничение обмена информацией неизбежно искажает процесс обучения. В то же время, стремление к высокой точности может ослабить механизмы конфиденциальности, делая систему более уязвимой для атак, направленных на восстановление исходных данных. Поэтому, разработка эффективных алгоритмов, способных поддерживать оптимальное соотношение между этими двумя критически важными аспектами, остается одной из центральных задач в области федеративного обучения, требующей компромиссов и инновационных подходов к защите данных без значительной потери в производительности модели.
Уязвимость федеративного обучения кроется в том, что, несмотря на кажущуюся анонимность, обновления моделей могут раскрывать конфиденциальную информацию о данных, используемых для обучения. Эти обновления, передаваемые центральному серверу, не являются полностью обезличенными и содержат следы индивидуальных характеристик обучающих выборок каждого клиента. Злоумышленник, анализируя эти обновления, способен реконструировать детали исходных данных, включая личные сведения или конфиденциальную информацию, что ставит под угрозу приватность пользователей. Даже незначительные изменения в обновлениях, отражающие специфику данных конкретного клиента, могут быть использованы для идентификации или получения информации о данных, что делает необходимым разработку и внедрение эффективных механизмов защиты, способных скрыть эти следы и обеспечить надежную конфиденциальность.
Для обеспечения конфиденциальности данных клиентов в условиях федеративного обучения требуется разработка инновационных защитных механизмов, способных противостоять сложным атакам. Исследования показывают, что существующие методы защиты часто оказываются недостаточными перед лицом продвинутых техник, направленных на извлечение информации о персональных данных из обновлений моделей. Разрабатываются новые подходы, включающие в себя дифференциальную приватность, гомоморфное шифрование и безопасные многосторонние вычисления, призванные усилить устойчивость системы к различным видам атак, таким как инверсия моделей и атаки на основе членства. Эффективность этих механизмов оценивается на основе компромисса между уровнем защиты и сохранением полезности модели, что является ключевой задачей в области конфиденциального машинного обучения.
Глубокая утечка данных: как взломать федеративное обучение
Атаки глубокой утечки данных (DLA) представляют серьезную угрозу для федеративного обучения (FL), поскольку позволяют восстанавливать обучающие изображения на основе общих обновлений модели. В процессе DLA злоумышленник анализирует градиенты, передаваемые участниками обучения, и итеративно реконструирует конфиденциальные данные, игнорируя стандартные механизмы защиты конфиденциальности. Суть атаки заключается в том, что градиенты, отражающие вклад каждого участника в процесс обучения, содержат информацию об исходных данных, которую можно извлечь и использовать для восстановления изображений, используемых при обучении модели. Это делает FL уязвимым к утечке конфиденциальной информации, даже при использовании методов, направленных на защиту данных.
Атаки глубокой утечки данных (DLA) используют информацию о градиентах, передаваемых в процессе федеративного обучения, для поэтапной реконструкции исходных обучающих изображений. Вместо прямого доступа к данным, злоумышленник анализирует обновления модели, отправляемые клиентами, извлекая из них информацию, достаточную для восстановления чувствительных данных. Данный подход обходит стандартные механизмы защиты конфиденциальности, такие как дифференциальная приватность или локальное дифференциальная приватность, поскольку не требует прямого доступа к данным, а лишь наблюдает за процессом обучения. Итеративный процесс реконструкции позволяет постепенно уточнять изображение, используя градиентный спуск для минимизации разницы между реконструированным и исходным изображением, что делает атаку эффективной даже при ограниченном количестве доступных обновлений модели.
Эффективные атаки глубокой утечки данных (DLA) активно используют методы регуляризации, в частности, Total Variation Regularization (TVR), для повышения качества реконструируемых изображений. TVR, применяемый в процессе восстановления данных из обновлений модели, способствует снижению шума и артефактов, что позволяет получить более четкие и детализированные изображения. Этот метод минимизирует сумму абсолютных разностей между соседними пикселями, эффективно сглаживая изображение и улучшая визуальную точность реконструируемых данных, тем самым облегчая идентификацию чувствительной информации, содержавшейся в исходных тренировочных данных. TVR(u) = \in t \sqrt{|\nabla u(x)|^2 + \epsilon^2} dx, где u — реконструируемое изображение, ∇ — оператор градиента, а ε — небольшое значение, предотвращающее деление на ноль.
Методы регуляризации, такие как L2-регуляризация и пакетная нормализация (Batch Normalization), предназначенные для повышения производительности модели при обучении, могут непреднамеренно облегчить проведение атак глубокой утечки данных (Deep Leakage Attacks, DLA). L2-регуляризация, ограничивая величину весов модели, способствует более гладким градиентам, что упрощает процесс реконструкции изображений на основе обмена обновлениями модели. Аналогично, пакетная нормализация, нормализуя активации слоев, снижает внутреннее ковариационное смещение, также приводя к более стабильным и предсказуемым градиентам, которые могут быть использованы злоумышленниками для восстановления конфиденциальных данных из обновлений модели. Таким образом, хотя эти методы улучшают обобщающую способность модели, они одновременно повышают её уязвимость к атакам, направленным на утечку информации об обучающих данных.

Улучшение реконструкции с помощью генеративных потоков
Для повышения качества реконструкции в методе дифференциальной конфиденциальности (DLA) нами исследуется применение априорных оценок на основе генеративных моделей сопоставления потоков (Generative Flow Matching). Данный подход предполагает использование предварительно обученной модели сопоставления потоков в качестве обучаемого шумоподавителя, что позволяет эффективно уточнять реконструируемые изображения и преодолевать ограничения, присущие традиционным методам регуляризации. Результаты экспериментов на наборе данных CIFAR-10 демонстрируют превосходство предлагаемого метода: достигнуты значения PSNR 20.861, SSIM 0.621, LPIPS 0.288 / 0.087 и минимальное значение FMSE 0.669, что превосходит показатели существующих альтернативных подходов.
Использование модели Flow Matching в качестве обучаемого шумоподавителя позволяет эффективно уточнять реконструированные изображения и преодолевать ограничения традиционных методов регуляризации. В отличие от фиксированных регуляризаторов, Flow Matching адаптируется к особенностям данных, что приводит к более точному восстановлению деталей и снижению артефактов. Этот подход позволяет моделировать сложные распределения данных, что особенно важно при реконструкции изображений с высокой степенью детализации или шума. Обучаемый шумоподавитель, реализованный на основе Flow Matching, способен эффективно отделять полезный сигнал от шума, обеспечивая более качественную реконструкцию по сравнению с традиционными методами, основанными на ручных настройках параметров регуляризации.
Использование генеративных моделей для повышения качества реконструкции изображений, хотя и обеспечивает более реалистичные и точные результаты, одновременно увеличивает риски для конфиденциальности. Повышенная точность реконструкции позволяет восстанавливать детали, которые ранее были скрыты или размыты, что потенциально позволяет извлекать чувствительную информацию из реконструированных данных. Это особенно актуально в сценариях, где исходные данные содержат личную информацию, такую как лица или конфиденциальные документы, и требует тщательной оценки и внедрения мер по защите конфиденциальности, таких как дифференциальная конфиденциальность или федеративное обучение, для смягчения этих рисков.
Качество реконструкции изображений было оценено с использованием метрик PSNR (Peak Signal-to-Noise Ratio) и SSIM (Structural Similarity Index) на наборе данных CIFAR-10, достигнув значений 20.861 и 0.621 соответственно. Дополнительно, были получены низкие значения метрик LPIPS (Learned Perceptual Image Patch Similarity) — 0.288 / 0.087, и минимальное значение FMSE (Fréchet Inception Distance) — 0.669, что демонстрирует превосходство разработанного метода над существующими подходами к реконструкции изображений на данном наборе данных.

Оценка и смягчение рисков конфиденциальности в FL
Исследования показали, что атаки на основе дифференциального локального анализа (DLA) представляют собой серьезную угрозу для систем федеративного обучения (FL). В ходе экспериментов на популярных наборах данных, таких как CIFAR-10 и Tiny-ImageNet, продемонстрирована эффективность DLA в извлечении конфиденциальной информации из обученных моделей. Анализ показал, что даже при децентрализованной структуре FL, злоумышленник, имеющий доступ к локальным обновлениям моделей, может успешно реконструировать фрагменты исходных данных, использованных в обучении. Эти результаты подчеркивают необходимость разработки надежных механизмов защиты конфиденциальности, способных противостоять подобным атакам и обеспечить безопасность пользовательских данных в системах федеративного обучения.
Исследования показали, что оценка конфиденциальности федеративного обучения (FL) требует обязательного учета атак, направленных на реконструкцию данных. Эти атаки, используя информацию, передаваемую в процессе обучения, способны восстановить чувствительные данные, содержащиеся в локальных наборах данных участников. Игнорирование возможности реконструкции может привести к ошибочной оценке уровня защиты персональных данных. Анализ уязвимости FL-систем к подобным атакам позволяет выявить слабые места и разработать эффективные стратегии защиты, гарантирующие конфиденциальность информации, участвующей в обучении моделей, даже при распределенной структуре данных и обучения.
В ходе экспериментов с набором данных Tiny-ImageNet была достигнута величина SSIM (Structural Similarity Index) равная 0.444. Этот показатель демонстрирует превосходство разработанного подхода над существующими методами в контексте реконструкции данных. Высокое значение SSIM указывает на значительную способность восстановления исходных изображений из параметров обученной модели федеративного обучения, что подчеркивает потенциальную уязвимость системы к атакам, направленным на извлечение конфиденциальной информации. Полученный результат свидетельствует о необходимости дальнейшей разработки и внедрения более эффективных механизмов защиты приватности в системах федеративного обучения, особенно при работе с изображениями.
Необходимость дальнейших исследований связана с тем, что различные схемы агрегации в федеративном обучении, такие как FedAvg и FedSGD, могут по-разному влиять на уязвимость системы к атакам. В частности, способы объединения локальных моделей, используемые в каждой схеме, могут создавать различные «слабые места», которые злоумышленники могут использовать для извлечения конфиденциальной информации. Изучение взаимодействия между конкретной схемой агрегации и типом атаки позволит более точно оценить риски и разработать эффективные контрмеры. Например, определенные схемы могут быть более устойчивы к атакам на основе реконструкции, в то время как другие могут быть более подвержены атакам, направленным на извлечение градиентов. Понимание этих нюансов критически важно для создания действительно безопасных и конфиденциальных систем федеративного обучения.
Для создания устойчивых и сохраняющих конфиденциальность систем федеративного обучения (FL) критически важным представляется исследование и внедрение таких методов, как дифференциальная приватность, Dropout и гомоморфное шифрование. Дифференциальная приватность позволяет добавлять контролируемый шум к данным или результатам обучения, чтобы скрыть индивидуальную информацию, сохраняя при этом общую полезность модели. Технология Dropout, применяемая во время обучения, случайным образом отключает нейроны, предотвращая чрезмерную зависимость модели от отдельных признаков и снижая риск утечки данных. Гомоморфное шифрование, в свою очередь, позволяет выполнять вычисления непосредственно над зашифрованными данными, обеспечивая конфиденциальность на протяжении всего процесса обучения и исключая необходимость дешифрования информации на центральном сервере. Комбинированное применение этих методов открывает перспективы для создания действительно безопасных и надежных систем FL, способных эффективно решать задачи машинного обучения, не ставя под угрозу конфиденциальность пользовательских данных.
В статье описывается новый метод утечки данных в условиях федеративного обучения, использующий генеративные модели. Авторы демонстрируют, как даже защищённые обновления могут быть использованы для реконструкции конфиденциальной информации. Впрочем, ничего нового. Как говорил Дэвид Марр: «Всё новое — это просто старое с худшей документацией». И действительно, утечки данных существовали всегда, просто теперь у них более сложные алгоритмические «обёртки». Авторы предлагают Flow Matching, но в конечном итоге, это лишь ещё один способ заставить старые уязвимости работать новыми способами. Продакшен найдёт способ сломать элегантную теорию, это лишь вопрос времени.
Что Дальше?
Представленная работа, безусловно, добавляет ещё один инструмент в арсенал атакующих. Ещё одна элегантная математическая модель, превращающаяся в головную боль для дата-сайентистов. Разумеется, защита, как всегда, будет отставать. Вероятно, последующие исследования сосредоточатся на усложнении моделей дифференциальной приватности, пытаясь хоть как-то скрыть следы, оставленные этими самыми «генеративными» методами. Но история учит, что любое усложнение защиты — это лишь временная передышка перед следующим прорывом в области атак.
Интересно, как далеко можно зайти в использовании подобных атак для выявления предвзятостей в федеративном обучении. Ведь, по сути, реконструкция данных — это возможность увидеть, что скрывается за усреднёнными обновлениями. Но, конечно, этические аспекты будут тщательно игнорироваться до тех пор, пока не произойдёт очередной громкий скандал. Тесты на приватность — это, как известно, форма надежды, а не гарантия.
В конечном итоге, вся эта гонка вооружений напоминает попытку построить песчаный замок во время прилива. Рано или поздно, вода всё равно смоет всё, что было построено. И тогда придётся признать, что данные — это всего лишь информация, и её утечка — это неизбежный побочный эффект любой сложной системы. Автоматизация, конечно, спасёт нас… до тех пор, пока скрипт не удалит продакшн.
Оригинал статьи: https://arxiv.org/pdf/2601.15049.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- H ПРОГНОЗ. H криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
2026-01-23 02:38