Автор: Денис Аветисян
Новый подход к отбору обучающих данных позволяет значительно повысить эффективность обучения больших языковых моделей сложным задачам, требующим логических рассуждений.
Предлагается метод, основанный на построении иерархического дерева навыков и отборе данных, ориентированных на слабые места модели в решении задач математического рассуждения.
Несмотря на впечатляющую производительность больших языковых моделей в сложных задачах рассуждения, их дистилляция в более компактные модели требует значительных объемов размеченных данных. В работе «Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation» предложен новый подход к дистилляции, основанный на приоритетном отборе данных и обучении с учетом иерархии навыков. Разработанный фреймворк позволяет значительно повысить эффективность обучения, фокусируясь на слабых сторонах модели и явно структурируя процесс решения задач. Может ли подобный подход открыть новые пути к созданию компактных и эффективных систем рассуждения, требующих минимального объема обучающих данных?
Иллюзия Знаний: Ограничения Масштаба в Больших Языковых Моделях
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) часто демонстрируют трудности при решении сложных задач, требующих логических умозаключений. Их производительность нередко оказывается хрупкой и подверженной ошибкам даже при незначительных изменениях в формулировке вопроса. Наблюдается, что БЯМ оперируют скорее статистическими закономерностями в данных, нежели настоящим пониманием смысла, что приводит к неспособности обобщать знания и применять их в новых, нестандартных ситуациях. Эта особенность проявляется в склонности к поверхностному анализу информации и неспособности выявлять причинно-следственные связи, ограничивая их применение в областях, требующих глубокого когнитивного анализа и критического мышления.
Несмотря на впечатляющий прогресс в увеличении размеров языковых моделей, простое наращивание числа параметров не всегда приводит к пропорциональному улучшению их способности к рассуждениям. Исследования показывают, что дальнейшее увеличение масштаба моделей дает все меньше прироста в решении сложных логических задач, что указывает на необходимость поиска более целенаправленных подходов к развитию искусственного интеллекта. Вместо бездумного увеличения параметров, акцент должен быть сделан на разработке новых архитектур, методов обучения и стратегий отбора данных, способных эффективно использовать существующие ресурсы и раскрывать потенциал моделей для более глубокого понимания и логического вывода. Такой подход позволит преодолеть текущие ограничения и создать системы, способные к действительно интеллектуальному поведению.
Существующие методы отбора данных для обучения больших языковых моделей, такие как LIMO и s1, демонстрируют ограниченную эффективность в развитии навыков сложного рассуждения. Они оперируют с каждым фрагментом информации как с равноценным вкладом в процесс обучения, не учитывая разницу в сложности и требуемом уровне экспертизы для его усвоения. В результате, модели подвергаются воздействию как простых, так и крайне сложных примеров без дифференцированного подхода, что приводит к усредненному, а не углубленному пониманию. Подобный подход препятствует формированию надежных навыков рассуждения, поскольку модель не получает достаточной практики в решении задач, соответствующих ее текущему уровню компетенции, и, следовательно, не может эффективно наращивать сложность решаемых задач.
Целенаправленное Обучение: Фокус на Слабых Сторонах
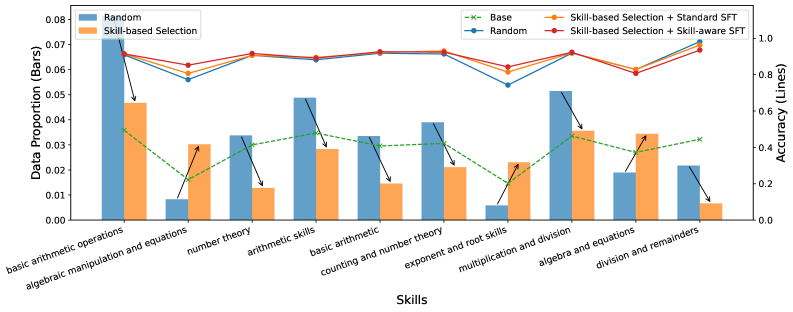
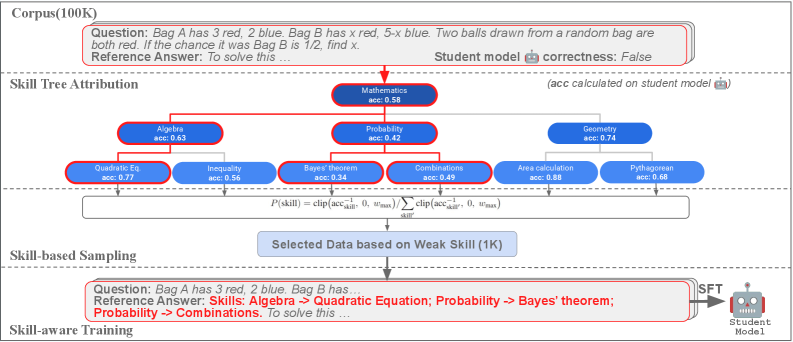
Метод выбора данных с учетом навыков (Skill-Aware Data Selection) основывается на приоритезации обучающих данных, направленных на устранение слабых мест модели, определенных с помощью иерархического дерева навыков (Hierarchical Skill Tree). Этот подход предполагает предварительный анализ возможностей модели и выявление конкретных навыков, в которых она демонстрирует недостаточную производительность. В процессе формирования обучающего набора данных предпочтение отдается примерам, требующим применения именно этих слабых навыков, что позволяет целенаправленно улучшить соответствующие аспекты работы модели. Использование иерархической структуры позволяет детализировать навыки и фокусироваться на конкретных областях для оптимизации.
Метод атрибуции навыков (Skill Attribution) позволяет установить соответствие между решаемыми задачами и конкретными навыками, необходимыми для их выполнения. Этот процесс заключается в анализе структуры задачи и определении, какие навыки из иерархического дерева навыков (Hierarchical Skill Tree) критически важны для ее успешного решения. В результате формируется отображение задач на навыки, что дает возможность целенаправленно отбирать обучающие данные, фокусируясь на тех областях, где модель демонстрирует наибольшие недостатки. Такая целевая курация данных значительно повышает эффективность обучения и позволяет оптимизировать производительность модели в конкретных областях.
Применение метода отбора данных, ориентированного на слабые стороны модели (Skill-Aware Data Selection), демонстрирует измеримое повышение производительности по сравнению со стандартными техниками отбора. В ходе экспериментов с моделями Qwen3-4B и Qwen3-8B зафиксировано увеличение показателя Avg@8 на 1,6% и 1,4% соответственно, при использовании всего 1000 примеров дистилляции. Данный результат подтверждает эффективность фокусировки на областях, где модель демонстрирует наименьшую компетентность, для улучшения общей точности и производительности.
Углубление Понимания: Обучение с Учетом Навыков и Дистилляция Рассуждений
Обучение с учетом навыков (Skill-Aware Training) является расширением подхода целевого отбора данных посредством дообучения (Fine-Tuning). В отличие от простого выбора данных, соответствующего определенным навыкам, данный метод явно включает в процесс обучения последовательности навыков (skill chains). Это позволяет модели не только изучать отдельные навыки, но и понимать, как они связаны друг с другом и как их применять в комплексе для решения более сложных задач. Использование skill chains в процессе обучения обеспечивает более эффективное усвоение знаний и улучшает способность модели к обобщению и решению новых задач, требующих последовательного применения различных навыков.
Метод дистилляции рассуждений (Reasoning Distillation) использует мощную модель-учитель DeepSeek-R1 для передачи способностей к рассуждению на более компактные и эффективные модели Qwen3-4B и Qwen3-8B. В процессе дистилляции, модель-учитель генерирует ответы на обучающие примеры, а затем модели Qwen3-4B и Qwen3-8B обучаются имитировать эти ответы, перенимая, таким образом, навыки логического мышления и решения задач, присущие DeepSeek-R1. Этот подход позволяет создать более компактные модели, сохраняющие при этом высокую производительность в задачах, требующих сложных рассуждений.
В процессе обучения моделей Qwen3-4B и Qwen3-8B, применение skill-aware аугментации позволило добиться дополнительного прироста точности, измеренного как Avg@8, на 0.8% и 1.3% соответственно. Этот прирост был достигнут поверх улучшения, полученного за счет использования skill-based отбора данных, что демонстрирует эффективность комбинированного подхода к формированию обучающей выборки и повышению производительности моделей в задачах, требующих применения цепочек навыков.
Подтверждение Эффективности: Результаты и Оценка
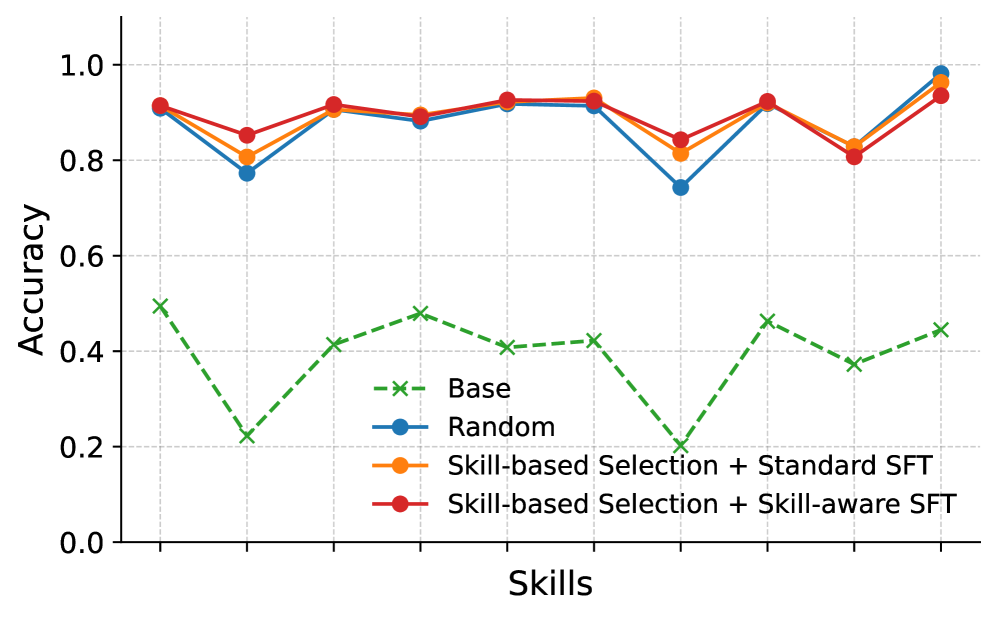
Оценка с использованием метрики Avg@8 продемонстрировала существенные улучшения в производительности моделей Qwen3, что подтверждает эффективность подхода, ориентированного на навыки. Данный показатель, измеряющий точность среди первых 8 предложенных ответов, выявил значительный прогресс в решении сложных задач, требующих логического мышления и анализа. В ходе экспериментов наблюдалось повышение способности моделей к более точной интерпретации вопросов и выдаче релевантных ответов, что свидетельствует об успешной интеграции механизма учета навыков в архитектуру Qwen3 и открывает перспективы для дальнейшей оптимизации в области искусственного интеллекта.
Для всесторонней оценки и сопоставления различных методов решения сложных задач, была разработана EvalTree — специализированная иерархическая структура навыков. Эта система представляет собой тщательно организованную древовидную структуру, в которой каждый узел соответствует конкретному навыку или подзадаче, необходимому для успешного выполнения более сложных рассуждений. EvalTree позволяет проводить детальный анализ производительности моделей, выявляя сильные и слабые стороны в различных областях знаний и навыков. Благодаря такой структуре, исследователи получают возможность не только оценить общую эффективность, но и точно определить, какие конкретно навыки требуют дальнейшего улучшения, что способствует более целенаправленной разработке и совершенствованию систем искусственного интеллекта, способных к сложному рассуждению.
Исследования показали, что применение метода отбора данных, основанного на навыках, привело к заметному улучшению точности моделей Qwen3 на сложных эталонных тестах. В частности, на тесте AMC23, модель Qwen3-8B продемонстрировала повышение точности на 3.2%, а на AIME2024, модель Qwen3-4B — на 2.4%. Эти результаты свидетельствуют о том, что целенаправленный отбор обучающих данных, учитывающий специфические навыки, позволяет значительно повысить способность моделей к решению сложных задач, требующих логического мышления и анализа. Полученные улучшения подтверждают эффективность предложенного подхода и его потенциал для дальнейшей оптимизации производительности языковых моделей в области рассуждений.
Представленное исследование демонстрирует стремление к упрощению сложного процесса обучения больших языковых моделей. Акцент на выборе данных, основанном на иерархическом древе навыков, позволяет модели целенаправленно улучшать слабые стороны, избегая избыточности. Это напоминает подход, который ценил Пол Эрдеш: «Математика — это искусство находить закономерности в хаосе». В данном случае, хаос — это огромный объем неструктурированных данных, а закономерность — это выявление ключевых навыков, необходимых для эффективного обучения. Ясность в определении этих навыков и фокусировка на них — это минимальная форма любви к процессу обучения, приводящая к более эффективной дистилляции рассуждений.
Что Дальше?
Представленная работа, хоть и демонстрирует улучшение эффективности дистилляции рассуждений, лишь слегка отодвигает завесу над истинной сложностью обучения языковых моделей. Упор на структурирование навыков — шаг верный, но сама иерархия умений представляется конструкцией условной. Истинное понимание требует не просто идентификации навыков, а осознания их взаимосвязи, что пока выходит за рамки формализации.
Очевидным направлением исследований является расширение понятия “навыка”. Полагаться исключительно на математические задачи — упрощение. Необходимо учитывать контекст, неопределенность, и, что самое сложное, — способность к адаптации. Модель, овладевшая навыком в узких пределах, едва ли может считаться разумной.
В конечном итоге, задача состоит не в увеличении объема данных, а в повышении качества их представления. Иногда, кажущаяся простота — признак глубинного непонимания. Элегантность решения — не в количестве параметров, а в минимальном количестве необходимых. И, возможно, тишина — информативнее любого алгоритма.
Оригинал статьи: https://arxiv.org/pdf/2601.10109.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
2026-01-19 04:11