Автор: Денис Аветисян
Исследователи предлагают инновационный фреймворк DeFlow, позволяющий отделить моделирование поведения от оптимизации стратегии для повышения стабильности и эффективности обучения с подкреплением на основе готовых данных.
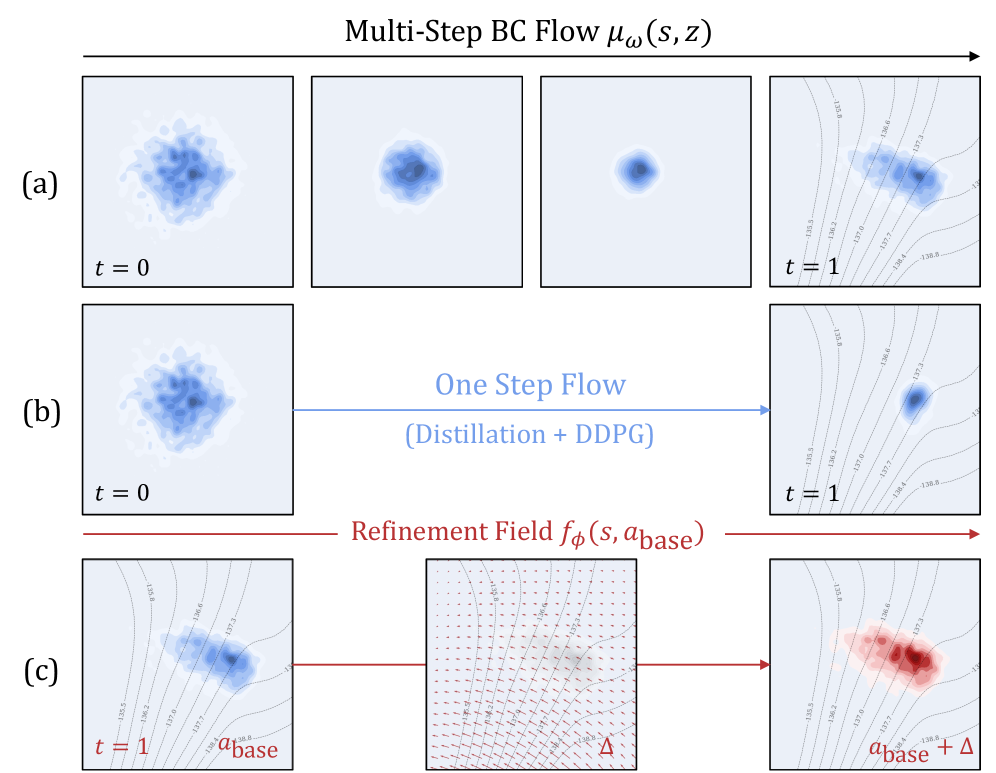
DeFlow использует flow matching и модуль уточнения для преодоления компромисса между выразительностью модели и оптимизацией, достигая передовых результатов в обучении с подкреплением вне сети.
Обучение с подкреплением в автономном режиме часто сталкивается с трудностями в одновременном моделировании сложного поведения и оптимизации стратегии. В данной работе, ‘DeFlow: Decoupling Manifold Modeling and Value Maximization for Offline Policy Extraction’, представлен новый подход, использующий flow matching для точного захвата многообразий поведения и отдельный модуль уточнения политики. Этот метод позволяет добиться превосходной производительности и стабильности, избегая компромисса между выразительностью модели и оптимизацией, характерного для существующих решений. Сможет ли DeFlow стать основой для создания более эффективных и надежных автономных систем обучения с подкреплением?
Офлайн Обучение с Подкреплением: Вызов Статических Данных
Традиционное обучение с подкреплением, несмотря на свою эффективность, требует значительного количества взаимодействий со средой для формирования оптимальной стратегии поведения. Этот процесс часто оказывается непозволительной роскошью или попросту невозможным в реальных сценариях, где каждое взаимодействие может быть связано с высокими затратами, риском или ограничением по времени. Например, в робототехнике длительное обучение методом проб и ошибок может привести к повреждению оборудования, а в медицине — к негативным последствиям для пациентов. Поэтому необходимость в методах, способных эффективно извлекать знания из существующих, статичных наборов данных, становится всё более актуальной и востребованной в различных областях применения.
Обучение с подкреплением вне сети представляет собой перспективный подход, позволяющий извлекать знания из статических наборов данных, избегая необходимости дорогостоящего и длительного взаимодействия с реальной средой. Однако, данный метод сталкивается с серьезной проблемой — смещением распределения данных. Суть заключается в том, что политика, обученная на статичном наборе данных, может столкнуться с ситуациями, не представленными в исходных данных, что приводит к снижению эффективности и даже нестабильности. Это происходит из-за расхождения между распределением данных, на котором обучается политика, и распределением состояний, возникающих в процессе ее применения. Для решения этой проблемы разрабатываются инновационные методы, направленные на корректировку политики с учетом этого смещения и обеспечение ее надежной работы в новых, неизвестных ранее ситуациях.
Проблема расхождения в распределении данных представляет собой значительное препятствие для эффективного обучения политик в рамках обучения с подкреплением в автономном режиме. Когда политика, обученная на статичном наборе данных, начинает действовать в реальной среде, она может столкнуться с состояниями и действиями, которые плохо представлены в исходных данных. Это приводит к экстраполяции за пределы изученного распределения, что часто вызывает нестабильность и снижение производительности. Поэтому разработка инновационных подходов, способных смягчить это расхождение, является ключевой задачей. Исследователи активно изучают методы, такие как ограничение действий, взвешивание данных и консервативное обучение, чтобы гарантировать, что политика остается в пределах области, где данные надежны и обучение эффективно. Успешное решение этой проблемы позволит использовать ценные исторические данные для обучения интеллектуальных агентов без необходимости дорогостоящего и рискованного взаимодействия со средой.
DeFlow: Разделение Поведения и Политики — Новый Взгляд
DeFlow преодолевает ограничения обучения с подкреплением на основе исторических данных за счет разделения процесса обучения поведенческой модели и оптимизации политики. Традиционные подходы offline RL часто сталкиваются с проблемой несоответствия распределений между данными и политикой, что приводит к нестабильности и субоптимальным результатам. DeFlow решает эту проблему, сначала обучая модель, имитирующую базовое поведение, представленное в исторических данных, а затем оптимизируя политику на основе этой модели. Такое разделение позволяет избежать прямого обучения политики на данных, которые могут не отражать оптимальное поведение, и обеспечивает более стабильный и эффективный процесс обучения. Это особенно важно в задачах, где сбор новых данных невозможен или затруднителен.
DeFlow использует метод Flow Matching для моделирования базового распределения данных, полученных от экспертных демонстраций. Этот подход позволяет изучить генеративный процесс, который улавливает суть поведения эксперта, не требуя явного определения функции вознаграждения. Flow Matching преобразует задачу обучения с подкреплением в задачу плотностного моделирования, где целью является изучение непрерывного отображения из случайного шума в пространство действий. Обучение осуществляется путем минимизации расхождения между распределением сгенерированных данных и распределением экспертных данных, что обеспечивает возможность воспроизведения экспертного поведения и последующей его оптимизации.
В DeFlow модуль уточнения играет ключевую роль в улучшении действий, генерируемых моделью поведения. Этот модуль функционирует итеративно: на каждой итерации он принимает сгенерированное действие и, используя градиентный спуск или аналогичные методы оптимизации, корректирует его для достижения более высокой производительности. Корректировка производится на основе функции потерь, которая отражает расхождение между текущим действием и оптимальным, что позволяет постепенно приближать поведение агента к желаемому уровню. Такой подход позволяет преодолеть ограничения, связанные с несовершенством модели поведения, и добиться значительного улучшения результатов обучения в задачах обучения с подкреплением вне сети.
Для обеспечения соблюдения ограничений безопасности или производительности в процессе уточнения политики, DeFlow использует метод оптимизации с ограничениями, основанный на множителях Лагранжа. Этот подход позволяет формализовать ограничения как часть целевой функции, добавляя штрафные члены, пропорциональные нарушениям ограничений. L(x, \lambda) = f(x) + \lambda^T g(x), где f(x) — целевая функция, g(x) — вектор функций ограничений, а λ — вектор множителей Лагранжа. Оптимизация осуществляется путем нахождения седловой точки функции Лагранжа, что обеспечивает выполнение ограничений при максимизации или минимизации целевой функции. Использование множителей Лагранжа позволяет эффективно интегрировать требования безопасности и производительности непосредственно в процесс обучения политики, гарантируя, что полученная политика соответствует заданным критериям.
Flow Q-Learning: Одношаговая Оптимизация Политики — Простота и Эффективность
Flow Q-Learning развивает концепцию DeFlow, упрощая итеративный процесс уточнения политики до одношагового генератора. В DeFlow политика уточнялась последовательными итерациями, требующими значительных вычислительных ресурсов. Flow Q-Learning устраняет необходимость в этих итерациях, представляя политику в виде выходных данных единого генератора, обученного напрямую отображать состояния в действия. Это достигается за счет интеграции обученной модели потока в процесс обучения с подкреплением, позволяя оптимизировать политику за один шаг вместо многократных обновлений, что значительно повышает эффективность вычислений и скорость обучения.
Интеграция обученной модели потока с Q-обучением позволяет осуществлять непосредственную оптимизацию политики без необходимости итеративных обновлений. Традиционные методы требуют последовательного улучшения политики через множество циклов обучения и оценки. В Flow Q-Learning, обученная модель потока непосредственно отображает состояние в действие, а Q-обучение оценивает качество этого действия в данном состоянии. Это позволяет напрямую максимизировать ожидаемое вознаграждение, обходя этап итеративного уточнения политики и значительно повышая эффективность вычислений. Таким образом, политика оптимизируется как результат прямого отображения состояния в действие, управляемого обученной моделью потока и оцениваемого Q-функцией.
Реализация одношагового генератора в Flow Q-Learning позволяет упростить процесс оптимизации политики и повысить вычислительную эффективность. Вместо итеративного уточнения, как в DeFlow, политика генерируется за один шаг, что значительно снижает временные затраты и потребление ресурсов. Этот подход основан на прямой генерации оптимальной политики, минуя необходимость в последовательных обновлениях и пересчетах, что особенно важно для задач с высокой размерностью пространства состояний и действий. Оптимизация генератора осуществляется с помощью алгоритма обратного распространения ошибки во времени (Backpropagation Through Time), что обеспечивает эффективное обучение и быстрое схождение к оптимальному решению.
Обучение генератора в Flow Q-Learning осуществляется с использованием алгоритма обратного распространения ошибки во времени (Backpropagation Through Time, BPTT). BPTT позволяет эффективно вычислять градиенты функции потерь по отношению к параметрам генератора, учитывая временную зависимость в генерируемых последовательностях действий. В данном контексте, алгоритм разворачивает генератор во времени, создавая цепочку вычислений, через которую распространяется ошибка от функции потерь, определяемой Q-обучением. Это позволяет оптимизировать параметры генератора таким образом, чтобы максимизировать ожидаемое вознаграждение, полученное агентом при следовании сгенерированной политике. Эффективность BPTT обеспечивается его способностью обрабатывать последовательные данные и обновлять параметры модели на основе долгосрочных последствий действий.
Практическое Влияние и Сравнение с Аналогами
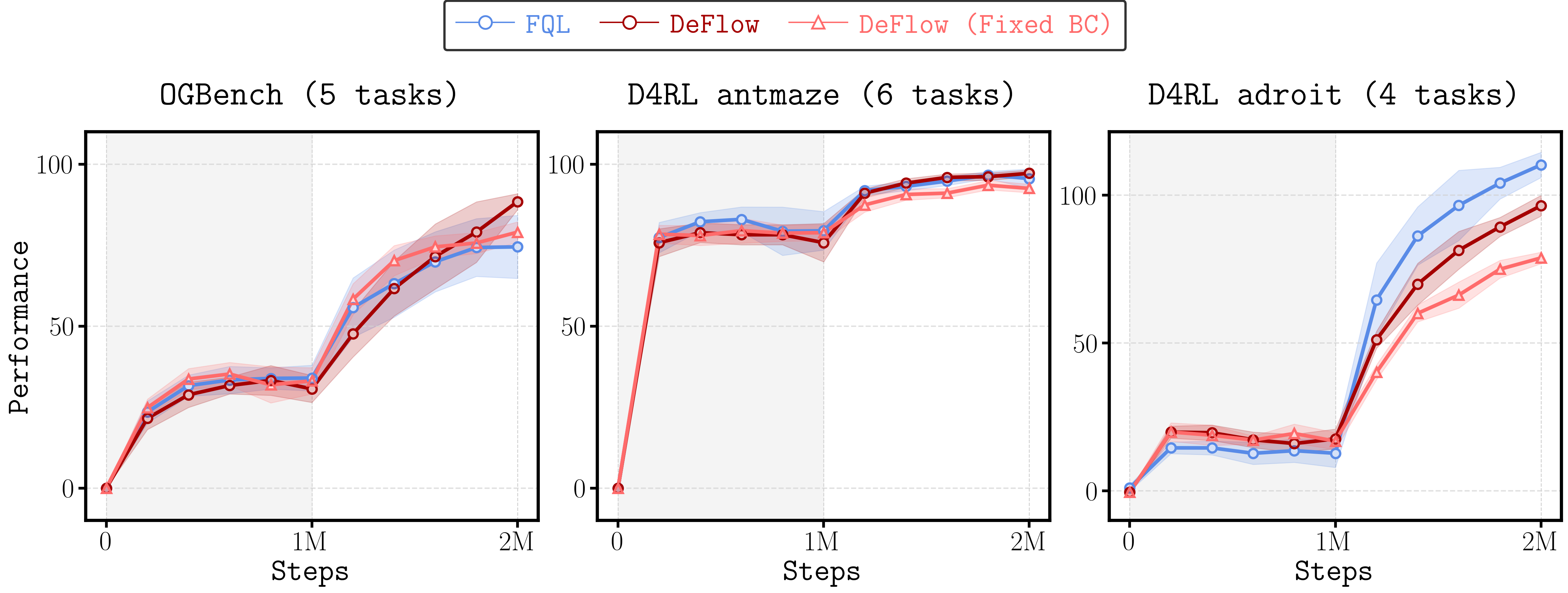
Развернутые эксперименты на общепринятых бенчмарках для обучения с подкреплением в режиме офлайн, включая OGBench и D4RL, наглядно демонстрируют превосходство DeFlow. Систематическое тестирование на широком спектре задач показало, что данный фреймворк стабильно превосходит существующие алгоритмы офлайн обучения с подкреплением, такие как FQL и методы, основанные на диффузии. Достигнутые результаты подтверждают эффективность DeFlow в извлечении полезной информации из ограниченных наборов данных, что делает его перспективным инструментом для решения сложных задач, где сбор данных в реальном времени затруднен или невозможен. В ходе экспериментов была зафиксирована высокая надежность и воспроизводимость полученных результатов, что свидетельствует о robustности подхода DeFlow.
Представленный фреймворк демонстрирует выдающиеся результаты в задачах обучения с подкреплением, достигая передовых или близких к ним показателей на обширном наборе стандартных offline RL бенчмарков, включающем 7373 задачи, а также в задачах Online-to-Offline (O2O), где обработано 1515 задач. Систематическое сравнение с существующими алгоритмами offline RL, такими как FQL и основанные на диффузии, последовательно подтверждает превосходство разработанного подхода. Полученные результаты свидетельствуют о значительном прогрессе в области обучения с подкреплением и открывают новые возможности для применения в сложных реальных сценариях, где доступ к данным ограничен или невозможен.
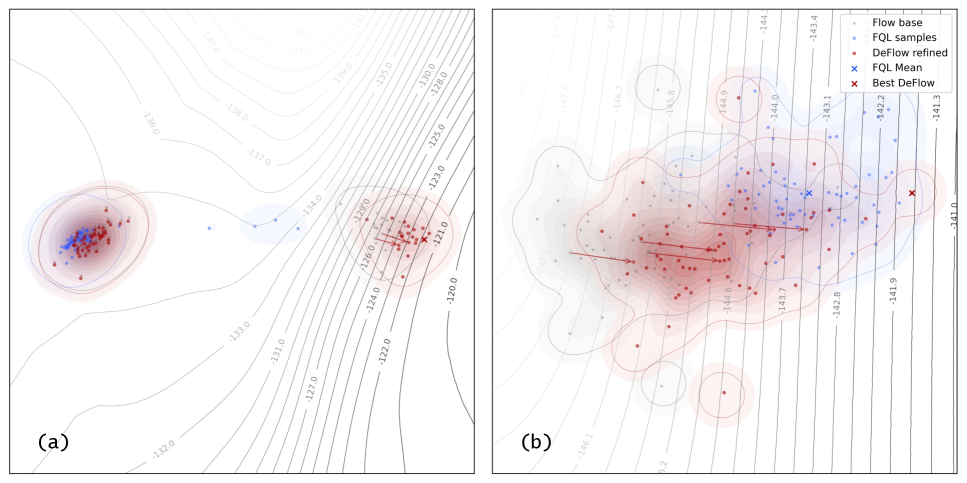
Анализ внутренней дисперсии действий выявил ключевое преимущество DeFlow — способность генерировать более реалистичные и разнообразные действия в процессе обучения с подкреплением. Исследование показало, что DeFlow эффективно исследует пространство действий, избегая застревания в локальных оптимумах и способствуя более полному освоению сложной среды. Высокая дисперсия указывает на то, что алгоритм не ограничивается узким набором действий, а активно ищет оптимальные стратегии, что особенно важно при работе с неполными или зашумленными данными. Это позволяет DeFlow адаптироваться к различным сценариям и демонстрировать превосходные результаты в задачах, требующих гибкости и способности к инновациям в принятии решений.
Исследования показали, что DeFlow демонстрирует передовые результаты в задачах перехода от онлайн к оффлайн обучению, превосходя существующие алгоритмы в решении сложных задач. Особенностью подхода является минимальная потребность в тонкой настройке гиперпараметров, что значительно упрощает процесс внедрения. В основе эффективности лежит эвристика, использующая дисперсию внутренних действий, для определения ограничений и обеспечения стабильности обучения. Это позволяет DeFlow эффективно адаптироваться к различным условиям и демонстрировать высокую производительность даже в сложных сценариях, где другие методы испытывают трудности.
Исследование демонстрирует стремление к преодолению традиционных ограничений в обучении с подкреплением, где часто наблюдается компромисс между выразительностью модели поведения и оптимизацией политики. Авторы предлагают подход DeFlow, разделяя эти два аспекта и используя flow matching для моделирования поведения, а затем модуль уточнения для улучшения политики. Это напоминает о словах Анри Пуанкаре: «Наука не состоит из ряда накопленных истин, а из методов открытия новых истин». DeFlow, подобно методу, открывает новые возможности в области обучения с подкреплением, позволяя достичь лучших результатов и стабильности, особенно в задачах, где данные ограничены, что соответствует главной идее исследования — разрыву с устоявшимися подходами и поиску более эффективных решений.
Куда же дальше?
Представленная работа, безусловно, смещает акценты в обучении с подкреплением вне сети, демонстрируя, как разделение модели поведения и оптимизации может обойти привычное противостояние между выразительностью и стабильностью. Однако, за каждой решенной задачей скрывается дюжина новых. Настоящая проверка DeFlow, и подобных ему подходов, лежит не в демонстрации превосходства на стандартных наборах данных, а в столкновении с данными, которые намеренно искажены, неполны или содержат скрытые зависимости. Как быстро система начнет «видеть» закономерности там, где их нет, и строить стратегии, основанные на иллюзиях?
Особый интерес представляет возможность применения принципов, заложенных в DeFlow, к задачам, где обратная связь не является мгновенной или полной. По сути, речь идет о расширении горизонтов планирования, но не за счет экспоненциального роста вычислительной сложности, а за счет более тонкого понимания структуры данных и выявления ключевых моментов, определяющих успех. Попытки объединить flow matching с методами, основанными на моделях мира, могут привести к появлению систем, способных к более гибкому и адаптивному обучению.
И, наконец, нельзя забывать о фундаментальном вопросе: насколько хорошо мы вообще понимаем природу «оптимальной» стратегии? В конечном счете, любая система обучения с подкреплением — это лишь приближение к идеалу, и признание этого факта — первый шаг к созданию действительно интеллектуальных машин. Дело не в том, чтобы создать алгоритм, который «побеждает», а в том, чтобы создать систему, которая постоянно учится и адаптируется, даже когда «победа» недостижима.
Оригинал статьи: https://arxiv.org/pdf/2601.10471.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-01-19 00:31