Автор: Денис Аветисян
Новый подход к исследованию среды позволяет агентам самостоятельно находить и осваивать сложные задачи, используя изменения в собственной стратегии поведения.
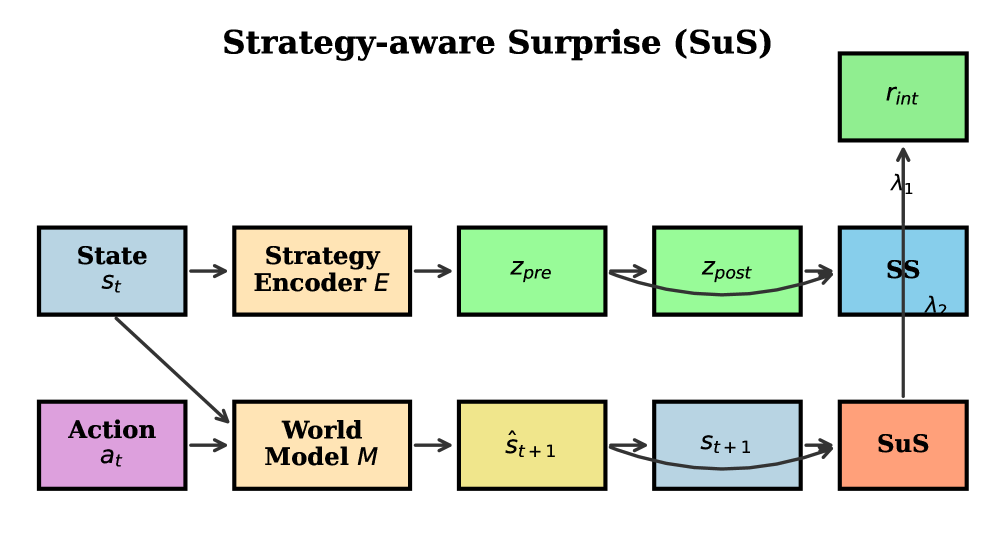
Предлагается фреймворк Strategy-aware Surprise (SuS) для повышения эффективности обучения с подкреплением за счет вознаграждения за изменения в поведенческих стратегиях агента.
Несмотря на успехи обучения с подкреплением, обеспечение эффективного исследования пространства состояний остается сложной задачей. В данной работе представлена новая структура внутренней мотивации — SuS: Strategy-aware Surprise for Intrinsic Exploration, — использующая несоответствие между предсказаниями и фактическими результатами, а также стабильность поведенческой стратегии агента. Предложенный подход позволяет существенно улучшить как точность, так и разнообразие решений в задачах, требующих рассуждений, например, в математической логике. Способно ли учитывать стратегические изменения агента стать ключевым фактором в создании более адаптивных и эффективных систем искусственного интеллекта?
За гранью традиционного исследования: вызовы обучения с подкреплением
Традиционные алгоритмы обучения с подкреплением зачастую сталкиваются с трудностями при работе с разреженными сигналами вознаграждения, что существенно ограничивает эффективность процесса исследования среды. Когда агент получает положительную обратную связь лишь изредка, ему становится сложно выявить причинно-следственные связи между своими действиями и желаемыми результатами. Это приводит к тому, что агент может застрять в неоптимальных состояниях, неспособный самостоятельно обнаружить полезные стратегии, поскольку значительная часть пространства действий кажется равноценной из-за отсутствия четких сигналов об успехе. В результате, обучение становится крайне медленным и требует огромного количества проб и ошибок, что делает применение таких методов непрактичным для многих сложных задач, особенно в реальных условиях, где получение частых вознаграждений не всегда возможно.
Для успешного обучения агентов в рамках обучения с подкреплением необходима достаточная обратная связь, однако многие реальные среды характеризуются редким получением сигналов вознаграждения. Это создает значительную проблему, поскольку агент испытывает трудности в установлении связи между своими действиями и полученными результатами, особенно в задачах, требующих долгосрочного планирования. Отсутствие частых сигналов затрудняет процесс исследования среды и эффективного формирования стратегии поведения. Агент может долгое время действовать, не получая никакой полезной информации, что приводит к замедлению обучения или даже к его полной остановке. Решение данной проблемы является ключевым для расширения области применения обучения с подкреплением в сложных и реалистичных сценариях.
Проблема разреженности вознаграждений существенно ограничивает применение обучения с подкреплением в сложных, реальных сценариях, требующих долгосрочного планирования. В ситуациях, где положительные сигналы встречаются крайне редко, агент испытывает трудности с установлением связи между своими действиями и конечным результатом. Это приводит к замедлению обучения и снижению эффективности в задачах, где успех зависит от последовательности действий, выполняемых в течение длительного периода времени. Например, в задачах управления роботом или разработки стратегии игры, где награда может быть получена только после выполнения нескольких сложных шагов, стандартные алгоритмы обучения с подкреплением часто оказываются неэффективными из-за недостатка информации для корректной оценки своих действий. Разработка методов, способных эффективно исследовать пространство состояний и извлекать полезные сигналы даже из редких вознаграждений, является ключевой задачей для расширения области применения обучения с подкреплением.
Внутренняя мотивация: источник самостоятельного исследования
Внутренняя мотивация (ВМ) представляет собой подход к обучению агентов, заключающийся в предоставлении им дополнительных, внутренних вознаграждений, основанных на собственной любознательности и прогрессе в обучении. В отличие от традиционных методов, полагающихся на внешние сигналы вознаграждения, ВМ стимулирует агента к активному исследованию среды и приобретению новых знаний, даже при отсутствии явных целей или задач. Эти дополнительные вознаграждения формируются на основе оценки новизны посещаемых состояний или степени улучшения модели предсказания динамики окружающей среды, тем самым поощряя поведение, направленное на максимизацию собственного обучения и расширение понимания.
Существует несколько подходов к реализации внутренней мотивации (IM). Методы, основанные на подсчете (count-based), стимулируют агента, вознаграждая за посещение ранее не встречавшихся состояний среды, тем самым поощряя исследование новых областей. Альтернативно, методы, использующие предсказание динамики среды (prediction-based), основаны на вознаграждении агента за уменьшение ошибки предсказания следующего состояния, что побуждает к изучению и моделированию окружающей среды. Оба типа подходов позволяют агенту активно исследовать и обучаться даже при отсутствии внешних наград.
Механизмы внутренней мотивации позволяют агентам проявлять активность в изучении незнакомых состояний даже при отсутствии внешних сигналов вознаграждения. Данные подходы основаны на стимулировании исследования среды, где новизна или прогресс в обучении становятся самоцелью. Агент, используя такие методы, самостоятельно формирует внутренние награды, пропорциональные степени своей неопределенности или скорости снижения этой неопределенности при взаимодействии с окружающей средой. Это позволяет агенту эффективно исследовать пространство состояний и собирать информацию, необходимую для решения более сложных задач в будущем, даже если текущая задача не предусматривает явного вознаграждения за исследование.
Удивление от стратегии: предвидение и вознаграждение за новизну
Метод «Удивление Стратегией» (Strategy Surprise, SuS) представляет собой новый подход к внутренней мотивации агентов, основанный на прогнозировании поведенческих тенденций, определяемых как «стратегии». В отличие от традиционных методов, которые вознаграждают за достижение конкретных целей, SuS фокусируется на вознаграждении за отклонение от предсказанных результатов. Это достигается путем обучения модели прогнозировать поведение агента и последующего предоставления вознаграждения, пропорционального величине расхождения между предсказанным и фактическим исходом действий. Такой подход стимулирует исследование новых стратегий и адаптацию к изменяющимся условиям, поскольку вознаграждение напрямую связано с неожиданностью поведения.
Механизм Strategy Surprise (SuS) использует кодировщик стратегий (Strategy Encoder) для преобразования наблюдаемых состояний в латентное пространство, представляющее поведенческие стратегии агента. Этот кодировщик формирует предсказание о наиболее вероятном исходе, основанном на текущей стратегии. Затем, агент получает вознаграждение, пропорциональное расхождению между предсказанным и фактическим исходом. Чем больше отклонение, тем выше вознаграждение, что стимулирует агента исследовать и адаптировать стратегии для повышения точности предсказаний и, следовательно, оптимизации поведения в среде.
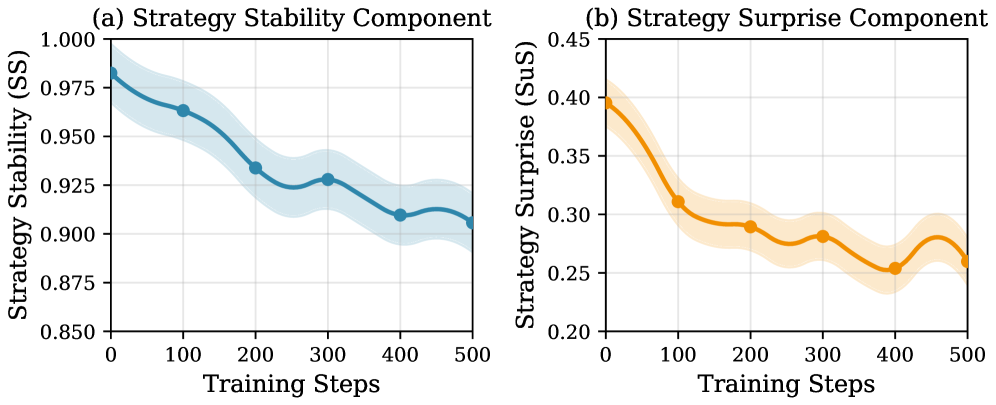
Комбинация подхода Strategy Surprise (SuS) и измерения Стабильности Стратегии (SS) способствует обнаружению и совершенствованию устойчивых поведенческих паттернов. SS количественно оценивает, насколько последовательно агент применяет определенную стратегию в различных ситуациях. Высокие показатели SS сигнализируют о надежности стратегии, что стимулирует агента к ее дальнейшей оптимизации. Низкие показатели, напротив, указывают на необходимость адаптации или поиска альтернативных подходов. Таким образом, SS выступает в роли метрики, позволяющей агенту оценивать и улучшать качество своих действий, способствуя развитию надежных и эффективных поведенческих шаблонов.
Использование Мировой Модели (World Model) значительно повышает эффективность предсказательных способностей системы Strategy Surprise (SuS). Мировая Модель позволяет агенту моделировать динамику окружающей среды и прогнозировать последствия своих действий, что необходимо для точной оценки вероятности различных стратегий. Улучшение предсказательной точности, обеспечиваемое Мировой Моделью, напрямую влияет на эффективность вознаграждения за отклонения от предсказанных результатов, тем самым стимулируя агента к исследованию и освоению новых, эффективных стратегий. Интеграция Мировой Модели позволяет SuS не просто реагировать на текущие события, но и предвидеть будущие, что критически важно для долгосрочного обучения и адаптации агента.
Проверка на задачах математического рассуждения
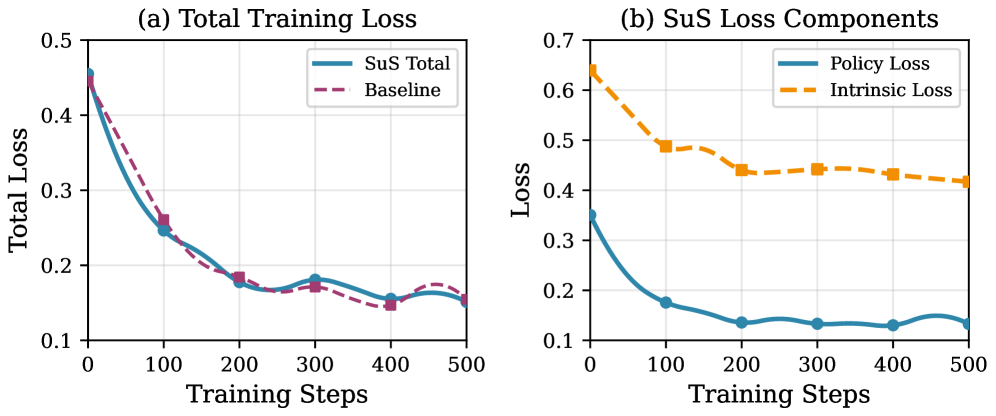
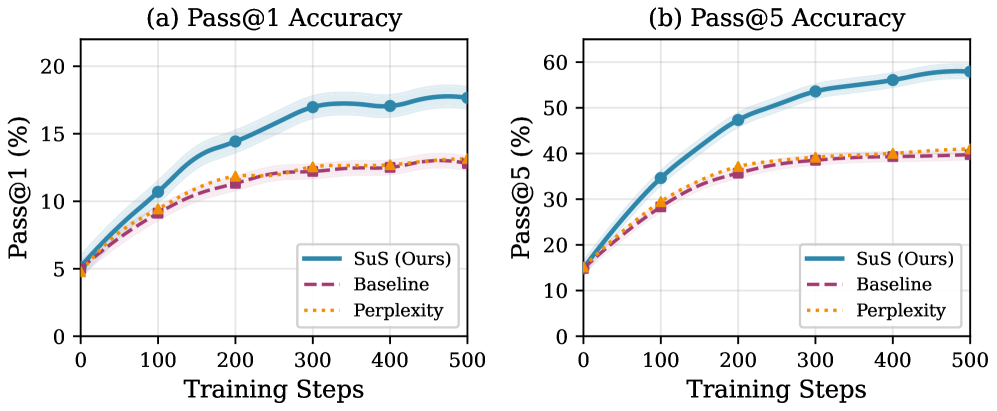
Применение данной структуры к задачам математического рассуждения продемонстрировало значительное повышение эффективности агентов, что подтверждается метриками Pass@1 и Pass@5. Исследования показали, что агенты, использующие предложенный подход, демонстрируют более высокую точность при решении математических задач по сравнению с базовыми методами. Улучшение производительности измерялось посредством оценки способности агента правильно ответить на задачу с первой попытки (Pass@1) и войти в топ-5 наиболее вероятных ответов (Pass@5), что свидетельствует о более эффективном процессе рассуждений и принятия решений. Результаты подчеркивают потенциал данной структуры для решения сложных задач, требующих логического мышления и математических навыков.
В ходе экспериментов с задачами на математическое рассуждение, разработанный подход SuS продемонстрировал значительное улучшение производительности. В частности, зафиксировано относительное повышение точности Pass@1 на 17.4% и Pass@5 на 26.4% по сравнению с базовыми методами. Эти результаты свидетельствуют о том, что SuS эффективно повышает способность агента находить правильные решения в сложных математических задачах, успешно справляясь с поиском оптимальных стратегий и демонстрируя превосходство в задачах, требующих последовательного логического мышления и точного вычисления.
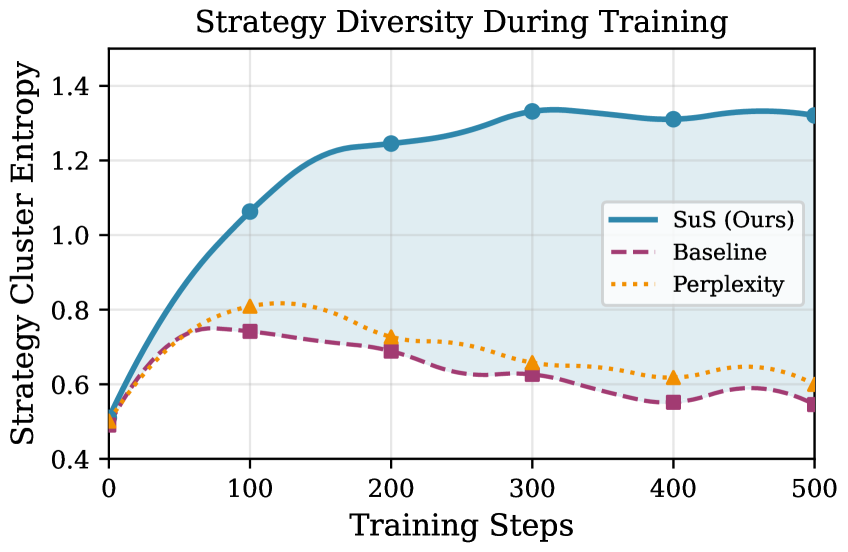
В рамках исследования было показано, что применение контрастивного обучения в кодировщике стратегий значительно улучшает представление поведенческих стратегий агента. Этот подход позволяет более эффективно кодировать и различать различные способы достижения целей, что, в свою очередь, повышает точность прогнозирования действий агента. Контрастивное обучение способствует формированию более информативных и устойчивых представлений стратегий, позволяя агенту лучше адаптироваться к новым задачам и более эффективно использовать накопленный опыт. Благодаря этому, агент способен точнее предсказывать оптимальные действия в сложных ситуациях, что положительно сказывается на общей производительности и эффективности решения поставленных задач.
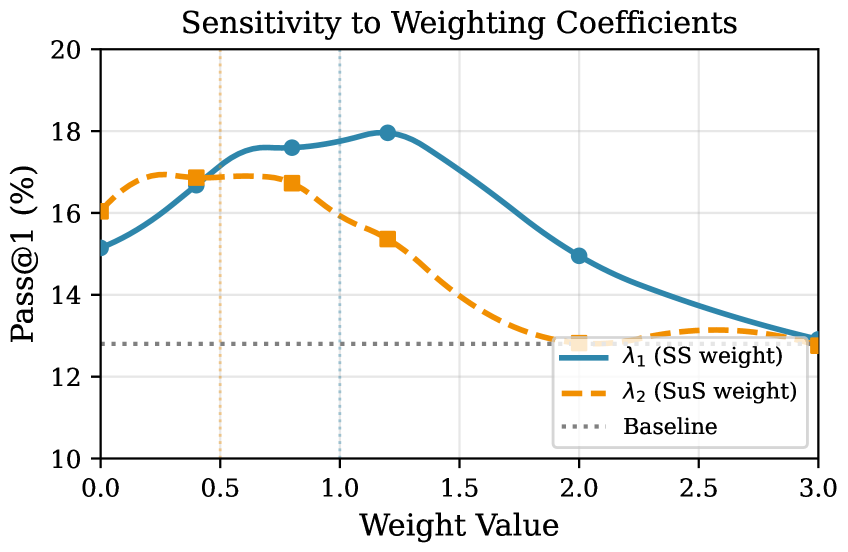
Исследования показали, что исключение любого из двух ключевых компонентов — стабильности стратегии (SS) или удивления от стратегии (SuS) — приводит к значительному снижению точности решения математических задач, оцениваемой метрикой Pass@5, примерно на 12.0%. Данный результат подчеркивает, что эффективность предложенного подхода обусловлена не отдельным использованием каждого компонента, а их синергией. Стабильность стратегии позволяет агенту фокусироваться на проверенных подходах, в то время как удивление от стратегии стимулирует исследование новых, потенциально более эффективных решений. Совместное применение этих двух принципов обеспечивает оптимальный баланс между эксплуатацией известных стратегий и исследованием новых путей, что критически важно для успешного решения сложных математических задач.
Полученные результаты указывают на то, что внутренняя мотивация, в особенности показатель «Удивление от стратегии» (SuS), способна эффективно решать проблему исследования в сложных задачах, ориентированных на достижение цели. В ситуациях, когда необходимо найти оптимальный путь решения, агенты часто сталкиваются с трудностями в изучении новых стратегий и оценке их потенциальной полезности. Механизм SuS, стимулируя агента к поиску и решению задач, представляющих для него наибольшую “новизну” или сложность, позволяет преодолеть эту проблему. Это приводит к значительному улучшению показателей успешности в задачах, требующих логического мышления и планирования, демонстрируя перспективность использования внутренней мотивации для разработки более адаптивных и интеллектуальных систем.
К эффективным и масштабируемым агентам
Использование метода LoRA (Low-Rank Adaptation) для тонкой настройки больших языковых моделей, таких как Qwen2.5-1.5B, представляет собой перспективный подход к созданию масштабируемых и эффективных агентов. Вместо полной переподготовки модели, требующей значительных вычислительных ресурсов, LoRA позволяет адаптировать ее к конкретным задачам путем обучения небольшого количества дополнительных параметров. Это существенно снижает затраты на обучение и развертывание, делая возможным создание сложных агентов, способных к решению разнообразных задач, даже на ограниченном оборудовании. Такой подход открывает возможности для широкого применения больших языковых моделей в интерактивных системах и автоматизированных процессах, где важна как производительность, так и экономичность.
Метод адаптации больших языковых моделей, известный как LoRA (Low-Rank Adaptation), представляет собой эффективный способ приспособить модель к конкретным задачам без необходимости полной переподготовки. Вместо изменения всех параметров модели, LoRA вводит небольшое количество обучаемых параметров, что значительно снижает вычислительные затраты и потребность в памяти. Это позволяет быстро и экономично настраивать модель для решения узкоспециализированных задач, сохраняя при этом большую часть её общих знаний. Такой подход особенно важен в условиях ограниченных ресурсов и необходимости масштабирования, поскольку позволяет создавать множество специализированных агентов на базе одной базовой модели, минимизируя затраты на обучение и развертывание.
Интеграция с системами внутренней мотивации, такими как SuS, открывает принципиально новые возможности для создания агентов, способных к непрерывному обучению и адаптации в меняющихся условиях. Вместо пассивного ожидания внешних инструкций, подобные агенты самостоятельно исследуют окружающую среду, формируя собственные цели и задачи, основанные на внутренней “любознательности” и стремлении к освоению нового. SuS, стимулируя агента к поиску и решению задач, представляющих для него наибольшую “новизну” или сложность, позволяет существенно расширить спектр решаемых задач и повысить эффективность обучения. Такой подход позволяет агентам не просто выполнять заданные команды, но и самостоятельно развиваться, приобретая новые навыки и знания, что особенно важно в динамичных и непредсказуемых средах, где заранее невозможно предусмотреть все возможные сценарии.
Перспективные исследования направлены на углубление взаимодействия между механизмами внутренней мотивации и большими языковыми моделями. Такое слияние позволит раскрыть весь потенциал последних, создавая агентов, способных не только эффективно выполнять заданные задачи, но и самостоятельно исследовать окружающую среду, приобретать новые знания и адаптироваться к изменяющимся условиям. Особое внимание уделяется разработке алгоритмов, которые позволят языковой модели определять и преследовать собственные цели, основанные на любопытстве и стремлении к самосовершенствованию, что приведет к созданию по-настоящему автономных и интеллектуальных систем. Дальнейшие исследования сосредоточены на оптимизации процессов обучения с подкреплением, учитывающих как внешние награды, так и внутреннюю мотивацию агента, что позволит достичь более высокой эффективности и устойчивости в различных сценариях.
Представленная работа исследует проблему эффективного исследования в обучении с подкреплением, акцентируя внимание на важности разнообразия стратегий агента. Данный подход перекликается с идеями Марвина Минского о необходимости создания систем, способных адаптироваться и учиться на протяжении всего жизненного цикла. Как однажды заметил Минский: «Наиболее перспективные исследования — это те, которые кажутся невозможными». Стратегия SuS, вознаграждающая изменения в поведении, направлена на преодоление стагнации, часто встречающейся в процессе обучения, и стимулирует агента к поиску новых, более эффективных решений. Это особенно важно при решении сложных задач, требующих нетривиального подхода и постоянной адаптации, таких как математическое рассуждение, где даже незначительные изменения в стратегии могут привести к значительному улучшению результатов.
Что дальше?
Предложенный подход, фиксируя изменения в поведенческой стратегии агента, безусловно, представляет собой шаг вперёд в области стимулирования внутренней мотивации. Однако, подобно любому коммиту в летописи, он лишь фиксирует состояние на момент публикации. Вопрос в том, как эта стратегия масштабируется. Попытки расширить её применение к более сложным задачам, несомненно, столкнутся с необходимостью учитывать не только изменения в стратегии, но и контекст этих изменений. Иначе, каждое улучшение рискует стать лишь локальной оптимизацией, не приносящей реальной пользы в долгосрочной перспективе.
Задержка в исправлении этих недочётов — неизбежный налог на амбиции. Особенно остро встаёт вопрос о взаимодействии SuS с моделями мира. Если агент формирует неверное представление о среде, изменение стратегии может лишь усугубить проблему, приводя к ещё более неэффективному исследованию. Необходимо разработать механизмы, позволяющие агенту критически оценивать свои собственные представления о мире и корректировать стратегию исследования на основе этой оценки.
И, наконец, не стоит забывать о фундаментальной проблеме: что есть «стратегия» в контексте искусственного интеллекта? Каждый шаг к её формализации — это упрощение, неизбежно вносящее искажения. В конечном итоге, задача состоит не в том, чтобы создать идеальную метрику стратегии, а в том, чтобы создать систему, способную адаптироваться к меняющимся условиям и учиться на своих ошибках, подобно любому организму, чья система неизбежно стареет.
Оригинал статьи: https://arxiv.org/pdf/2601.10349.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
2026-01-18 21:18