Автор: Денис Аветисян
Новый подход позволяет автоматически выявлять некорректно размеченные данные, повышая точность моделей машинного обучения.
В статье представлен адаптивный метод обнаружения ошибок разметки, использующий байесовский подход и геометрические свойства признаков в пространстве представлений.
Несмотря на прогресс в машинном обучении, точность моделей зачастую страдает из-за ошибок в маркировке данных, даже при экспертной аннотации. В работе, озаглавленной ‘Adaptive Label Error Detection: A Bayesian Approach to Mislabeled Data Detection’, предложен новый метод обнаружения ошибочной маркировки, использующий геометрические свойства признакового пространства, полученного из глубоких сверточных нейронных сетей, и байесовское моделирование. Предложенный подход, Adaptive Label Error Detection (ALED), демонстрирует повышенную чувствительность к ошибочным меткам без ущерба для точности, что подтверждено на медицинских изображениях. Способны ли подобные методы существенно улучшить качество обучающих данных и, как следствие, производительность моделей в различных областях?
Проблема Шумных Данных: Источник Ненадежности в Обучении
Машинное обучение, особенно в задачах классификации медицинских изображений, демонстрирует высокую чувствительность к шуму в данных, выражающемуся в неверных метках. Эта уязвимость обусловлена тем, что алгоритмы учатся на предоставленных данных, и ошибочные метки приводят к формированию неверных закономерностей. В результате, даже самые сложные модели могут выдавать неточные прогнозы, что особенно критично в медицинской диагностике, где точность играет решающую роль. Игнорирование шума в данных может существенно снизить надежность и эффективность алгоритмов, препятствуя их практическому применению и требуя разработки специализированных методов для выявления и смягчения последствий ошибочной разметки.
Наличие ошибочно размеченных данных оказывает существенное негативное влияние на производительность и надежность моделей машинного обучения. Этот эффект особенно заметен в критически важных областях, таких как медицинская визуализация, где даже небольшое количество неверных меток может привести к ошибочным диагнозам и неэффективному лечению. По сути, модель, обученная на зашумленных данных, усваивает неверные закономерности, что приводит к снижению точности прогнозирования и обобщающей способности. В результате, внедрение таких моделей в реальные приложения становится проблематичным, поскольку их результаты нельзя считать достоверными и заслуживающими доверия, что существенно ограничивает их практическую ценность и потенциальное влияние.
Традиционные методы машинного обучения зачастую не учитывают или недостаточно эффективно справляются с проблемой зашумленных меток в данных. В то время как алгоритмы оптимизируются для работы с «чистыми» данными, реальные наборы данных, особенно в таких областях как медицинская визуализация, неизбежно содержат ошибки в аннотациях. Это приводит к тому, что модели, обученные на зашумленных данных, демонстрируют снижение точности и обобщающей способности. В связи с этим, все большее внимание уделяется разработке так называемых «data-centric» решений, ориентированных не на усложнение самих алгоритмов, а на повышение качества и надежности исходных данных. Такие подходы включают в себя автоматическое выявление и исправление ошибок в разметке, а также использование методов робастного обучения, устойчивых к наличию зашумленных примеров.
Для создания надежных и эффективных систем машинного обучения, критически важно выявлять и смягчать влияние шума в данных, выражающегося в ошибочной разметке. Неточности в маркировке обучающих примеров приводят к снижению точности моделей, особенно в чувствительных областях, таких как медицинская диагностика по изображениям. Исследования показывают, что даже незначительный процент ошибочно размеченных данных может существенно ухудшить способность модели к обобщению и принятию верных решений. Разработка методов, способных автоматически обнаруживать и корректировать эти ошибки, становится ключевой задачей для повышения доверия к результатам, полученным с помощью машинного обучения, и обеспечения их практической применимости в реальных условиях.
Разнообразие Подходов к Выявлению Неправильных Разметок
Существующие методы обнаружения ошибочно размеченных данных можно разделить на две основные категории: ориентированные на модель и ориентированные на данные. К методам, ориентированным на модель, относятся, например, подходы, предложенные Reed et al., Goldberger et al. и SCELoss, которые используют предсказания модели и проверки согласованности для выявления потенциально ошибочных экземпляров. В свою очередь, к подходам, ориентированным на данные, относятся Confident Learning (CL), Mixup и INCV, которые анализируют собственные характеристики данных, применяя методы консистентностного обучения, аугментации данных и вероятностного моделирования для обнаружения несоответствий.
Модельно-ориентированные методы обнаружения некорректно размеченных данных используют предсказания модели и проверки на согласованность для выявления потенциально ошибочных экземпляров. Они часто включают сложные схемы перевзвешивания, такие как корректировка весов обучающих примеров на основе уверенности модели в их правильности или согласованности предсказаний при небольших возмущениях входных данных. Например, метод Reed et al. перевзвешивает примеры, основываясь на расхождении между предсказаниями модели на исходном и возмущенном изображении. Аналогично, метод Goldberger et al. использует оценку потерь для определения примеров, которые, вероятно, являются ошибочными, и перевзвешивает их соответствующим образом. Эти схемы перевзвешивания направлены на снижение влияния ошибочных данных на процесс обучения и повышение обобщающей способности модели.
Дата-центрические подходы к выявлению ошибочно размеченных данных анализируют собственные характеристики данных, а не поведение модели. Они используют такие методы, как consistency training, который предполагает, что небольшие возмущения входных данных не должны существенно изменять предсказания модели, выявляя тем самым несогласованности. Data augmentation, или увеличение объема данных путем создания модифицированных версий существующих примеров, позволяет оценить устойчивость модели к вариациям и обнаружить выбросы. Кроме того, применяются вероятностные модели, которые оценивают вероятность правильности метки на основе распределения данных, позволяя выявить аномальные примеры с низкой вероятностью.
Метод Mentor-Net реализует подход к обучению на основе учебного плана (curriculum learning), в котором приоритет отдается примерам с высокой уверенностью в метке. Это достигается путем обучения «наставнической» сети, которая предсказывает сложность каждого примера для основной сети. В процессе обучения, примеры с низкой сложностью (т.е. с высокой уверенностью в метке), представляются основной сети первыми, а затем постепенно добавляются более сложные примеры. Такой подход позволяет основной сети быстрее и эффективнее обучаться на надежных данных, снижая влияние потенциально ошибочных размеченных экземпляров на начальных этапах обучения и повышая общую точность модели.
Использование Пространства Признаков для Надежного Обнаружения: ALED
Адаптивное обнаружение ошибок разметки (ALED) представляет собой подход, ориентированный на данные, который явно использует векторные представления признаков (feature embeddings) для выявления некорректно размеченных образцов. В отличие от традиционных методов, ALED анализирует данные в пространстве признаков, а не напрямую работает с исходными метками. Это позволяет алгоритму выявлять экземпляры, чьи векторные представления существенно отличаются от представлений других образцов с той же меткой, что указывает на возможную ошибку в разметке. Применение ALED позволяет неявно учитывать характеристики данных и более эффективно идентифицировать проблемные образцы, улучшая общую производительность модели.
Метод Adaptive Label Error Detection (ALED) применяет техники снижения размерности, в частности, линейный дискриминант Фишера (Fisher Linear Discriminant), для повышения различительной способности векторных представлений данных. Этот подход позволяет преобразовать исходные признаки в новое пространство, где классы более четко разделены. Линейный дискриминант Фишера максимизирует межклассовую дисперсию и минимизирует внутриклассовую дисперсию, что способствует более эффективному выявлению выбросов, потенциально соответствующих ошибочно размеченным образцам. Улучшение различительной способности признаков является ключевым фактором, обеспечивающим более точное определение и последующую коррекцию ошибок в обучающей выборке.
Метод ALED определяет потенциально ошибочно размеченные образцы путем анализа геометрических свойств векторных представлений признаков. Анализ включает в себя выявление выбросов в пространстве признаков — точек, значительно удаленных от основной массы данных, соответствующих определенному классу. Такие выбросы, как правило, указывают на образцы, для которых метка не соответствует фактическому классу, поскольку их векторные представления отличаются от представлений других образцов того же класса. Идентификация этих выбросов основана на оценке расстояний между точками в многомерном пространстве признаков и выявлении тех, которые статистически отклоняются от общей картины распределения данных.
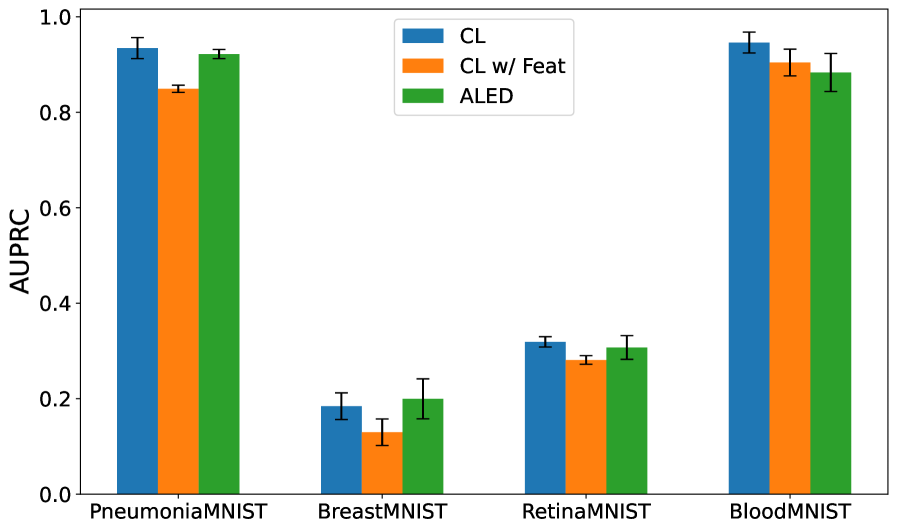
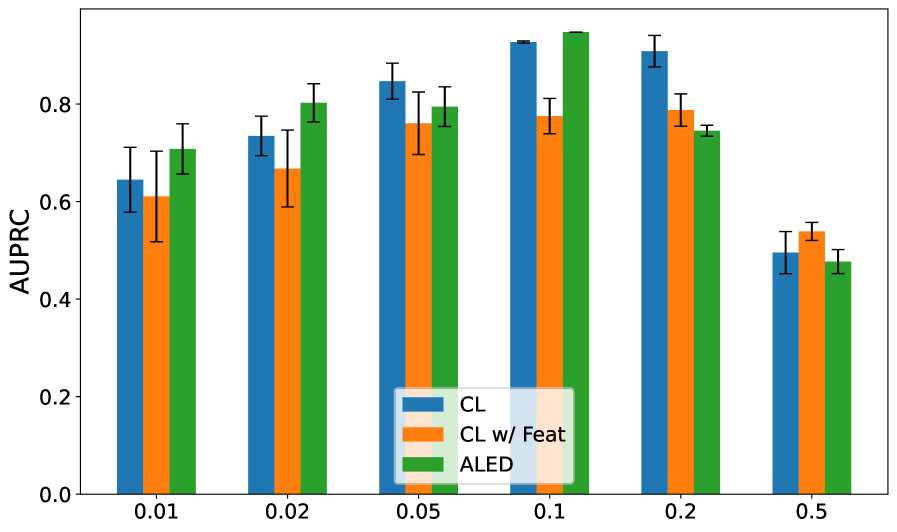
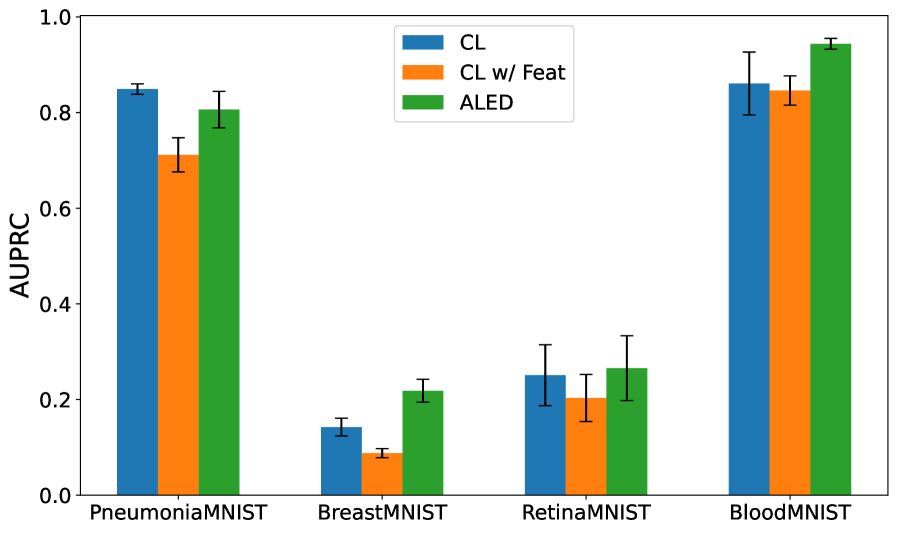
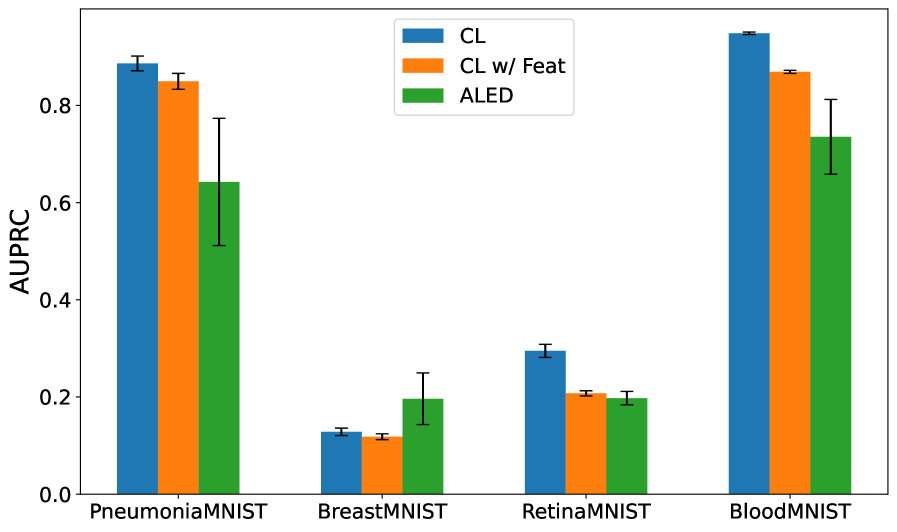
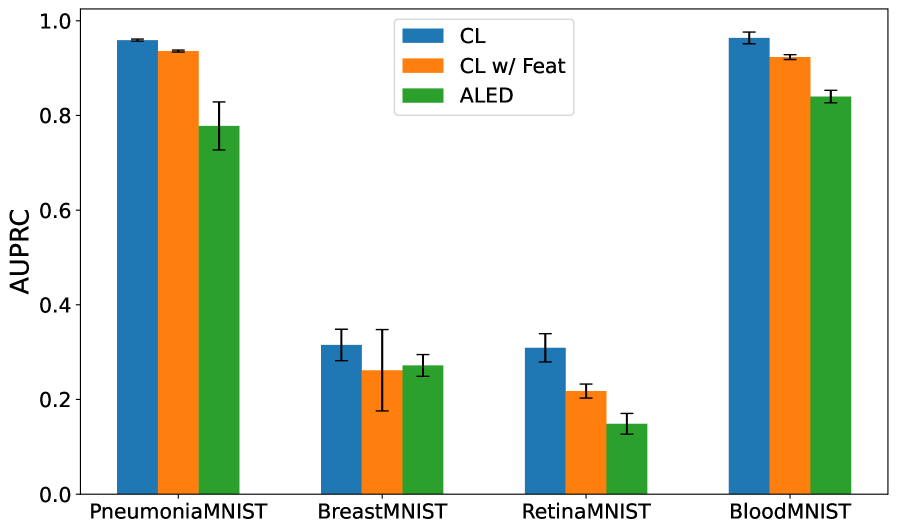
Метод ALED использует гауссовскую модель для выявления выбросов в пространстве признаков, что позволяет уточнить обучающую выборку. В результате применения данного подхода зафиксировано снижение ошибки на тестовых данных на 33.8%, что существенно превосходит показатели существующих методов. В частности, снижение ошибки при использовании ALED примерно в 5 раз выше, чем при использовании методов, основанных на Contrastive Learning (CL) с применением признаков.
Влияние на Надежность Модели: За пределами Обнаружения
Исследования показывают, что устранение шума в данных, в частности посредством методов, подобных ALED, значительно повышает надежность и способность к обобщению моделей машинного обучения. Процесс очистки обучающего набора данных от некорректных меток позволяет моделям более эффективно извлекать закономерности и демонстрировать повышенную производительность на ранее не встречавшихся данных. Этот подход особенно важен в областях, где точность прогнозов имеет решающее значение, например, в медицинской диагностике по изображениям, где даже небольшие ошибки могут иметь серьезные последствия. Улучшение качества обучающих данных не просто повышает точность модели, но и укрепляет уверенность в её результатах, открывая новые возможности для применения машинного обучения в реальных задачах.
Создание более чистого и точного набора данных для обучения является ключевым фактором повышения эффективности и обобщающей способности моделей машинного обучения. Когда модель обучается на данных, содержащих ошибки или неточности, её способность к правильной классификации новых, ранее не встречавшихся образцов существенно снижается. Устранение неверно размеченных данных позволяет модели более эффективно выявлять истинные закономерности и связи, что приводит к повышению точности прогнозов и снижению количества ложных срабатываний. В результате, модель приобретает способность к более надежной работе с реальными данными, что особенно важно в задачах, где требуется высокая степень достоверности, например, в медицинской диагностике или автоматическом анализе изображений.
Особая значимость коррекции неверно размеченных данных проявляется в областях, связанных с высоким риском, таких как классификация медицинских изображений. В этих сценариях даже незначительные ошибки в предсказаниях могут иметь серьезные последствия для здоровья пациентов. Поэтому, обеспечение максимальной точности моделей машинного обучения становится не просто желательным, но и жизненно необходимым. Методы, позволяющие выявлять и исправлять неверные метки, существенно повышают надежность диагностических систем, способствуя более точной и своевременной постановке диагноза, что, в свою очередь, открывает возможности для более эффективного лечения и улучшения прогноза для пациентов.
Исследования последовательно демонстрируют превосходство метода ALED в задачах машинного обучения, подтвержденное более высокими значениями метрик F_1 и AUPRC на различных наборах данных по сравнению с методами CL и CL с дополнительными признаками. Это указывает на способность ALED более эффективно выявлять и корректировать ошибочно размеченные данные, что, в свою очередь, значительно повышает надежность и обобщающую способность моделей. Такая точность в обработке данных особенно важна в критических областях, где от правильности прогнозов зависит многое, открывая новые возможности для применения машинного обучения в реальных сценариях и позволяя полностью реализовать его потенциал.
Исследование предлагает адаптивный подход к выявлению ошибочно размеченных данных, опираясь на геометрию признакового пространства. В этом стремлении к очистке данных проявляется не только техническая задача, но и философский принцип: упрощение ради ясности. Как заметил Давид Гильберт: «В каждой сложности требуется алиби». Подход ALED, выявляя и устраняя шум в данных, стремится к созданию более надежных и интерпретируемых моделей. Это соответствует идее о том, что абстракции стареют, принципы — нет: надежность модели определяется не сложностью архитектуры, а качеством входных данных и четкостью лежащих в основе принципов.
Что дальше?
Предложенный подход, безусловно, демонстрирует потенциал в выявлении ошибочной разметки, однако он, как и большинство решений, опирается на предположения о геометрии признакового пространства. Они назвали это «геометрией», чтобы скрыть панику перед непредсказуемостью реальных данных. Необходимо помнить, что гауссовские модели — это лишь приближение, и их адекватность может сильно варьироваться в зависимости от природы данных и архитектуры используемой нейронной сети. Следующим шагом представляется исследование более гибких методов моделирования распределения, возможно, с использованием непараметрических подходов или смесей более сложных распределений.
Более того, акцент на признаковых представлениях, полученных от уже обученной сети, неизбежно вносит предвзятость. Следует задуматься о подходах, которые могут выявлять ошибки разметки непосредственно на этапе обучения, возможно, с использованием механизмов внимания или самообучения. В конце концов, истинная зрелость заключается не в очистке данных после катастрофы, а в предотвращении её наступления.
Очевидно, что проблема ошибочной разметки не ограничивается лишь обнаружением и удалением “плохих” примеров. Необходимо исследовать, как использовать информацию об ошибках разметки для улучшения самой модели, например, путем корректировки весов или использования робастных функций потерь. Сложность — это тщеславие. Ясность — милосердие. И простота — высшая форма совершенства.
Оригинал статьи: https://arxiv.org/pdf/2601.10084.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
2026-01-18 07:55