Автор: Денис Аветисян
Новое исследование, основанное на анализе 100 триллионов токенов, показывает, как на практике применяются современные модели искусственного интеллекта и какие тенденции определяют их развитие.
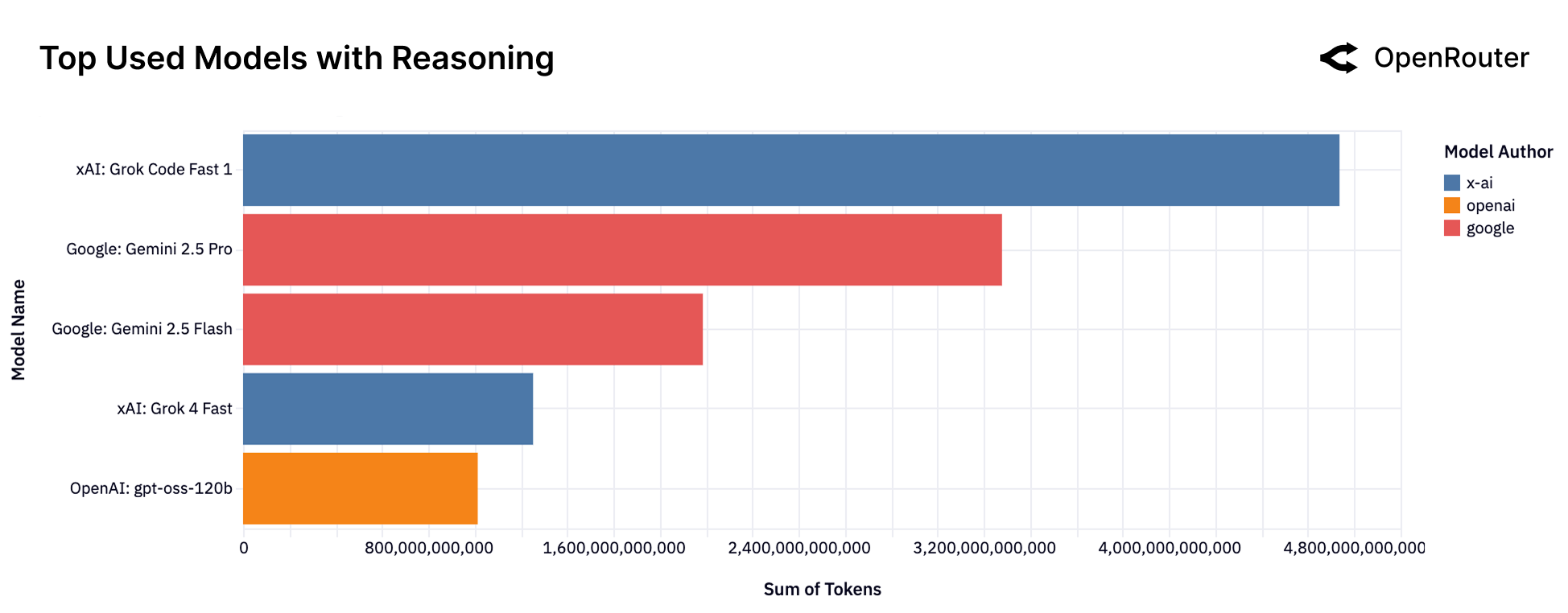
Эмпирический анализ использования моделей искусственного интеллекта с OpenRouter демонстрирует смещение в сторону агентного вывода, возрастающую роль открытых моделей и необходимость более комплексной оценки их эффективности.
Несмотря на стремительное развитие больших языковых моделей (LLM), эмпирическое понимание их реального использования оставалось фрагментарным. Настоящее исследование, озаглавленное ‘State of AI: An Empirical 100 Trillion Token Study with OpenRouter’, анализирует свыше 100 триллионов токенов данных с платформы OpenRouter, выявляя растущую популярность моделей с открытым исходным кодом, расширение сфер применения за пределы продуктивности, и тенденцию к агентному выводу. Полученные результаты подчеркивают, что фактические паттерны использования LLM существенно отличаются от первоначальных ожиданий, и что ранние пользователи демонстрируют устойчивую вовлеченность. Как эти данные могут помочь разработчикам и поставщикам инфраструктуры создавать более эффективные и адаптированные LLM-системы?
Зарождение Агентного ИИ: Выход за Рамки Простого Предсказания
Первые большие языковые модели демонстрировали впечатляющую способность к распознаванию закономерностей в данных, однако их возможности в области сложного, многоступенчатого рассуждения оставались ограниченными. Эти модели успешно предсказывали следующее слово в последовательности или генерировали текст, подобный обучающему корпусу, но испытывали трудности при решении задач, требующих планирования, анализа и применения знаний в новых контекстах. Вместо того чтобы активно строить логическую цепочку для достижения цели, они, по сути, оперировали вероятностями, основанными на статистическом анализе огромных объемов текста. Это ограничивало их применение в сценариях, где требовалось не просто воспроизводить существующие данные, а создавать новые решения и адаптироваться к изменяющимся условиям.
Переход к так называемому ‘агентному выводу’ — процессу, в котором модели самостоятельно планируют действия, выполняют их и анализируют результаты — требует принципиально новых архитектурных решений в области искусственного интеллекта. Традиционные модели, основанные на предсказании следующего слова, оказываются неспособны к сложным, многоступенчатым рассуждениям, необходимым для эффективного планирования и адаптации к изменяющимся условиям. Разработка систем, способных к самостоятельному решению задач, требует интеграции механизмов планирования, управления памятью и самооценки, что, в свою очередь, стимулирует появление новых нейросетевых структур и алгоритмов обучения, ориентированных на создание действительно автономных интеллектуальных агентов.
Современные языковые модели всё чаще демонстрируют способность выходить за рамки простого генерирования текста, переходя к использованию внешних инструментов для решения задач. Этот переход знаменует собой важный сдвиг в парадигме искусственного интеллекта, где модели не просто предсказывают следующий токен, а планируют последовательность действий, используя, например, поисковые системы, калькуляторы или даже другие специализированные программы. Такое взаимодействие с внешними ресурсами позволяет моделям получать доступ к актуальной информации, выполнять сложные вычисления и, в конечном итоге, решать задачи, которые были бы невозможны при работе только с имеющимися в памяти данными. Вместо того, чтобы быть просто генераторами текста, они становятся полноценными агентами, способными самостоятельно находить и использовать инструменты для достижения поставленной цели, что открывает новые перспективы в автоматизации и решении сложных проблем.
Архитектурные Инновации: Основа Агентских Возможностей
Модели нового поколения, такие как OpenAI o1 (Strawberry) и Anthropic Sonnet 2.1 и 3, демонстрируют значительный прогресс в области агентского рассуждения благодаря увеличению вычислительных ресурсов и расширенным возможностям для обдумывания и анализа. Повышенная вычислительная мощность позволяет этим моделям обрабатывать более сложные задачи и сценарии, а расширенные возможности для обдумывания обеспечивают более глубокий анализ входных данных и более обоснованные решения. Это проявляется в улучшенной способности к планированию и решению проблем, требующих многошаговых рассуждений и долгосрочного планирования.
Ключевые особенности современных моделей, обеспечивающих продвинутые возможности агентов, включают внутреннее многошаговое планирование и итеративную доработку решений. Реализация данного функционала опирается на использование структурированных токенов планирования инструментов, позволяющих модели последовательно определять и применять необходимые инструменты для достижения цели. Примером подобного подхода является архитектура модели Cohere Command R, где специальные токены явно обозначают планируемые действия с инструментами, обеспечивая более контролируемый и интерпретируемый процесс решения задач. Это позволяет модели не просто выполнять отдельные действия, а разрабатывать и совершенствовать сложные планы действий, повышая эффективность и надежность агента.
Современные языковые модели, такие как o1 от OpenAI и Sonnet 2.1 & 3 от Anthropic, демонстрируют повышенную эффективность за счет использования методов Retrieval-Augmented Generation (RAG) и сложных инструментов. RAG позволяет моделям получать доступ к внешним базам знаний и использовать релевантную информацию для улучшения ответов и решения задач. Одновременно, использование разнообразных инструментов, управляемых моделью, позволяет ей выполнять действия, выходящие за рамки простой генерации текста, например, поиск информации, выполнение вычислений или взаимодействие с другими системами, что существенно расширяет ее функциональные возможности и повышает точность результатов.
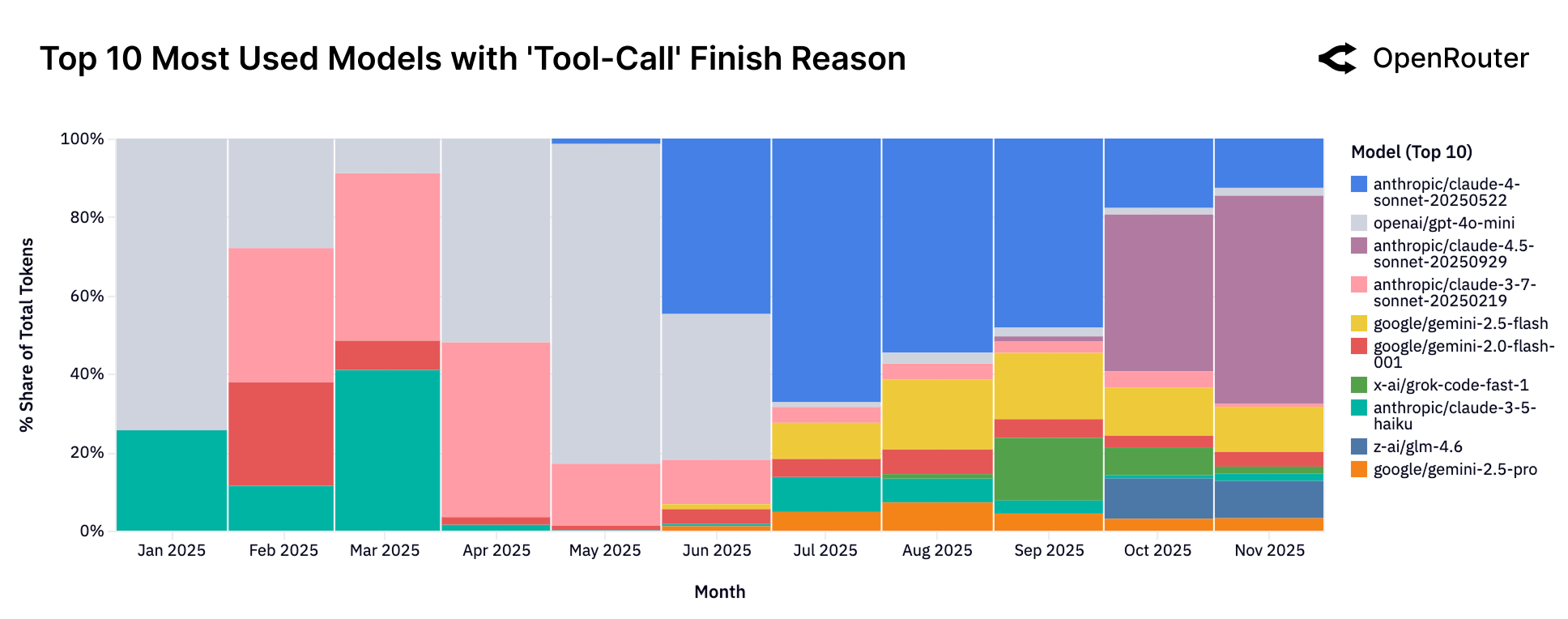
Наблюдая Реальное Использование: Паттерны и Тренды
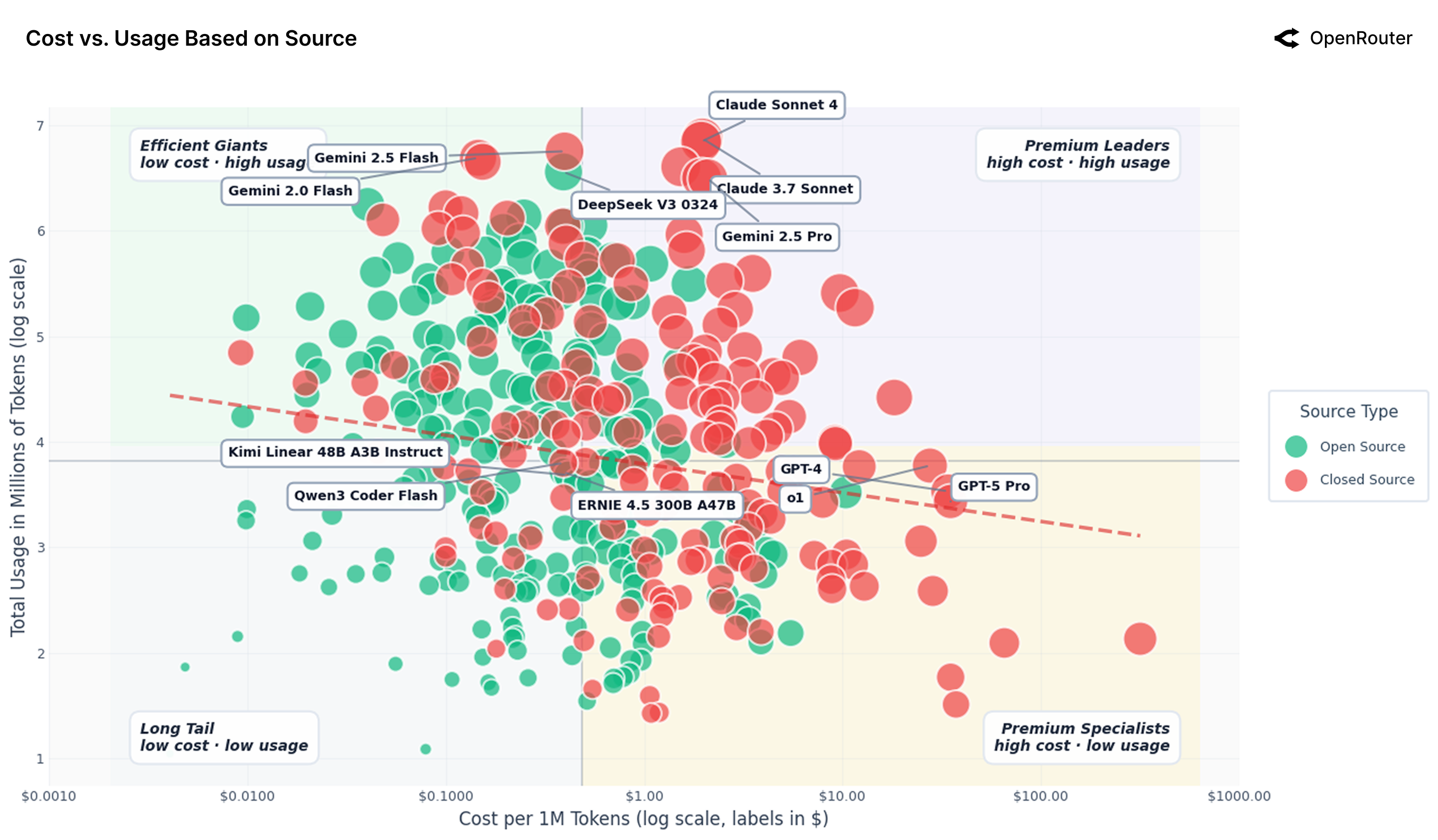
Платформа OpenRouter предоставляет уникальные данные об использовании больших языковых моделей (LLM), демонстрируя, что наибольший объем потребляемых токенов приходится на задачи программирования и ролевые игры. Анализ фактического использования показывает, что эти два типа задач совместно составляют значительную часть всей активности на платформе, превосходя другие категории применения. Данные, собранные OpenRouter, позволяют получить представление о реальных сценариях использования LLM, отличающихся от теоретических моделей и оценок, и подчеркивают важность этих двух категорий задач для текущего ландшафта LLM.
Платформа OpenRouter использует GoogleTagClassifier для детализированной категоризации запросов и ответов, что позволяет проводить анализ выполняемых задач. Данная система классифицирует контент на основе тегов, присваиваемых как входным запросам (prompts), так и сгенерированным ответам (completions). Это позволяет выявлять преобладающие типы задач, такие как программирование, ролевые игры, и другие, а также отслеживать изменение их популярности во времени и оценивать долю каждого типа в общем объеме потребляемых токенов. Точная классификация контента, обеспечиваемая GoogleTagClassifier, является ключевым инструментом для понимания реальных сценариев использования больших языковых моделей.
Анализ данных платформы OpenRouter демонстрирует растущую популярность агентного вывода (Agentic Inference) как в задачах программирования, так и в ролевых играх. Этот подход, характеризующийся использованием LLM для планирования и выполнения сложных задач, становится все более востребованным. В частности, задачи программирования теперь составляют более 50% от общего объема потребляемых токенов, что подтверждает значимость агентного вывода в контексте разработки программного обеспечения и автоматизации задач. Данная тенденция указывает на переход к более сложным и контекстно-зависимым рабочим нагрузкам, требующим от LLM не только генерации текста, но и способности к логическому мышлению и планированию.
Средняя длина промптов, обрабатываемых платформой OpenRouter, значительно возросла с 1,5 тысяч токенов до более чем 6 тысяч. Данный тренд указывает на переход к более сложным и насыщенным контекстом задачам, требующим от языковых моделей обработки большего объема входных данных. Увеличение длины промптов свидетельствует о расширении спектра решаемых задач и усложнении логики взаимодействия с моделями, что, в свою очередь, обуславливает потребность в более мощных и эффективных LLM.
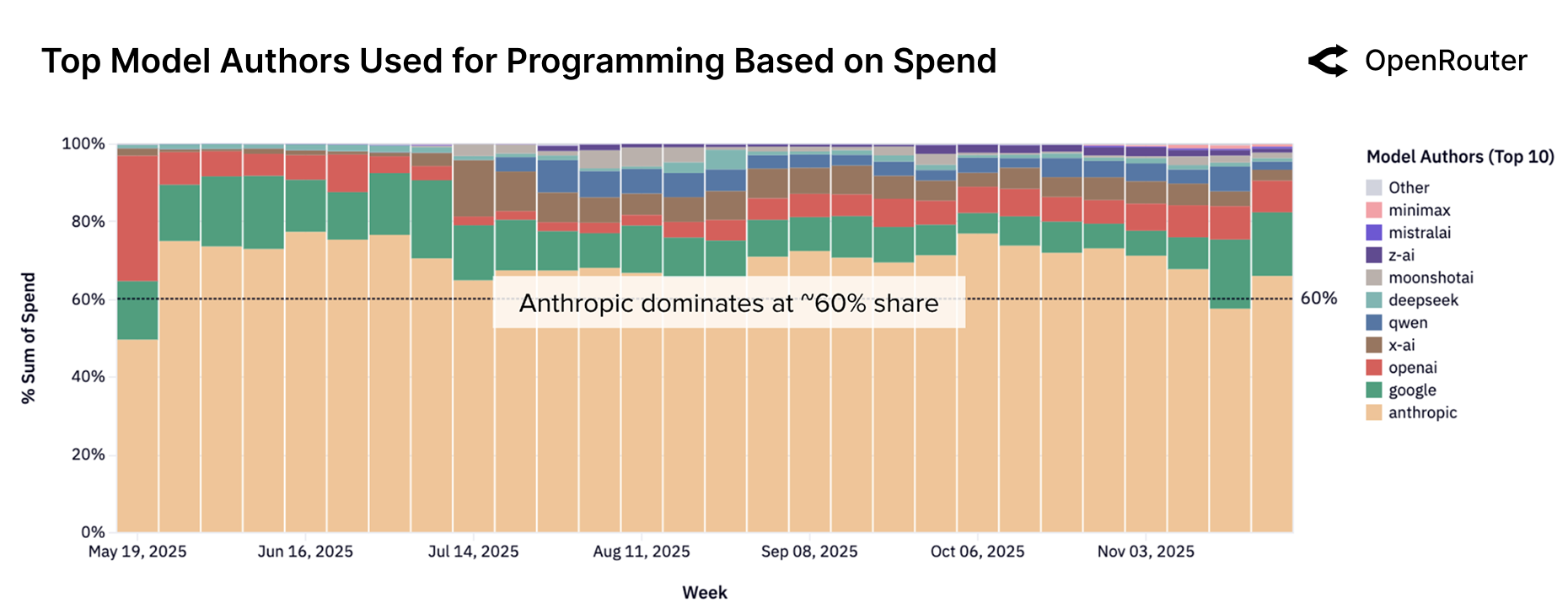
Экономические и Распределительные Последствия Масштаба
Анализ данных платформы OpenRouter демонстрирует чёткую взаимосвязь между стоимостью и динамикой использования больших языковых моделей. Наблюдается, что по мере увеличения доступности и снижения стоимости токенов, объемы их потребления растут экспоненциально. Данная тенденция ставит под вопрос долгосрочную устойчивость текущих траекторий развития, поскольку неограниченный рост потребления ресурсов может привести к истощению вычислительных мощностей и увеличению энергетической нагрузки. Исследование показывает, что необходимо более тщательно оценивать баланс между эффективностью моделей и общим уровнем их использования, чтобы избежать нежелательных последствий для экосистемы искусственного интеллекта и окружающей среды.
Исследования показывают, что повышение эффективности языковых моделей, несмотря на кажущуюся экономию ресурсов, может привести к парадоксу Джевонса. Этот феномен предполагает, что снижение стоимости использования больших языковых моделей (LLM) за счет оптимизации алгоритмов и инфраструктуры, напротив, стимулирует увеличение спроса и, следовательно, общего потребления вычислительных мощностей. Вместо ожидаемого снижения нагрузки на ресурсы, более эффективные модели могут привести к экспоненциальному росту числа запросов и задач, решаемых с их помощью, нивелируя преимущества оптимизации. Поэтому, для обеспечения устойчивого развития в области искусственного интеллекта, необходимо учитывать этот потенциальный эффект и разрабатывать стратегии, направленные на сдерживание избыточного потребления ресурсов, а не только на повышение эффективности самих моделей.
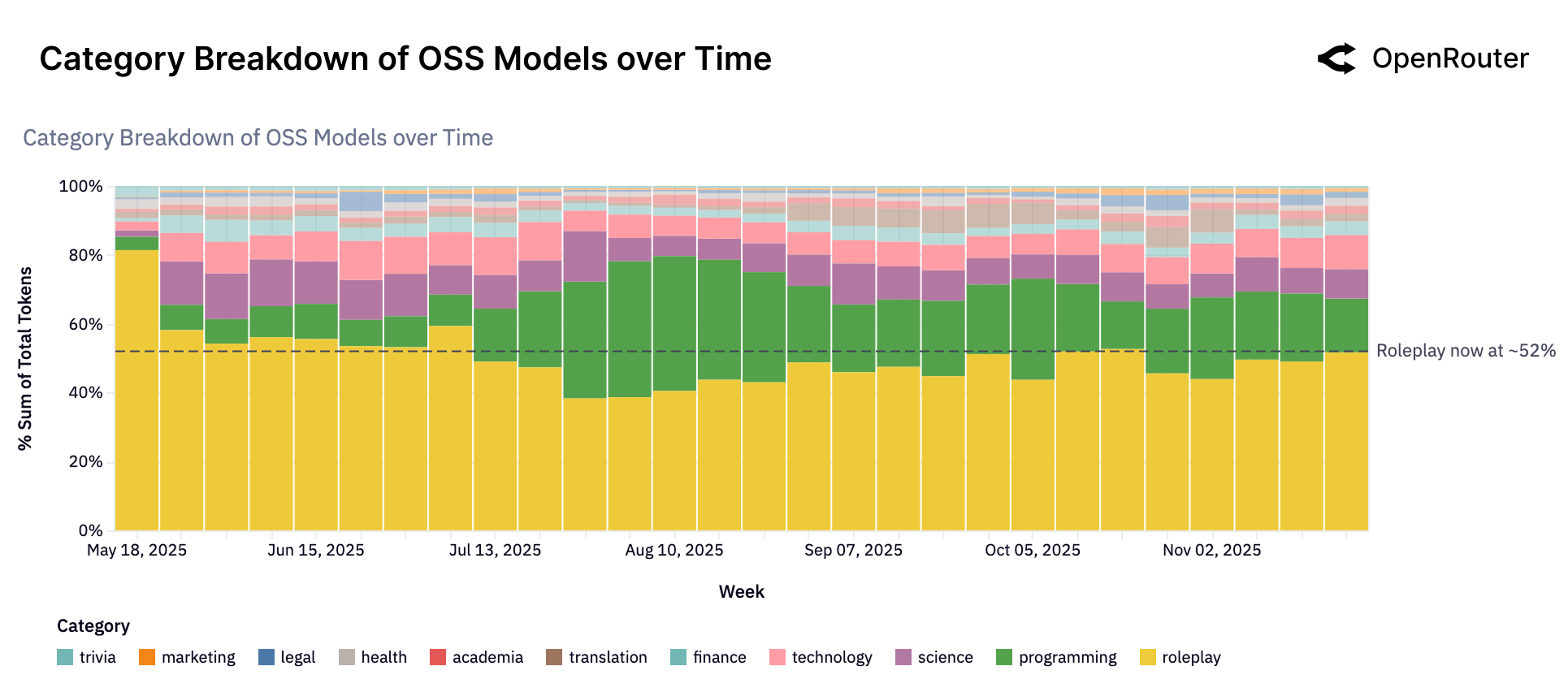
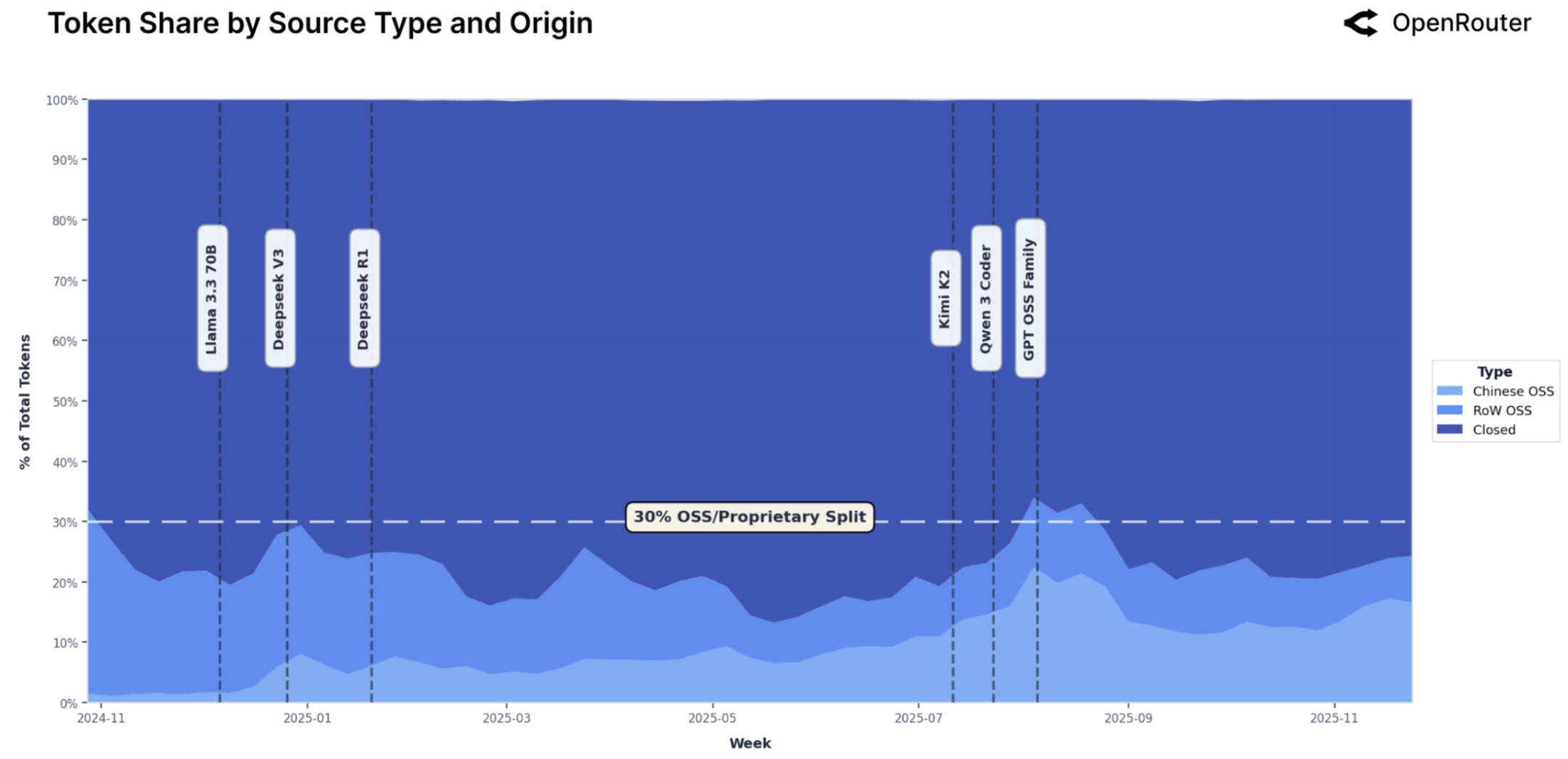
Географическое распространение моделей с открытым весом демонстрирует значительный потенциал для расширения доступа к передовым технологиям и стимулирования локальных разработок. Анализ показывает, что, хотя открытый исходный код позволяет сообществам по всему миру адаптировать и совершенствовать языковые модели, наблюдаются существенные различия в уровне участия и доступности ресурсов. В то время как определенные регионы, обладающие развитой инфраструктурой и квалифицированными специалистами, активно внедряют и развивают эти модели, другие сталкиваются с проблемами, связанными с ограниченным доступом к вычислительным мощностям, данным и экспертным знаниям. Это создает риск углубления цифрового разрыва и неравномерного распределения преимуществ от развития искусственного интеллекта, подчеркивая необходимость целенаправленных усилий по поддержке и развитию сообществ в регионах с ограниченными ресурсами.
Данные платформы OpenRouter демонстрируют значительный сдвиг в ландшафте больших языковых моделей: более 30% от общего объема обработанных токенов теперь приходится на модели с открытым исходным кодом. Этот показатель свидетельствует о растущей роли и влиянии открытых разработок в экосистеме LLM, что указывает на появление альтернативы проприетарным решениям и расширение возможностей для исследователей и разработчиков. Подобная тенденция может способствовать снижению барьеров для входа на рынок и стимулировать инновации, поскольку открытый доступ к моделям позволяет сообществу активно участвовать в их улучшении и адаптации к различным задачам. Это представляет собой фундаментальное изменение, которое, вероятно, продолжит набирать обороты в ближайшем будущем.
Будущие Направления: Длинный Контекст и Устойчивый Рост
Разработка окон длинного контекста является ключевым фактором для реализации сложных автономных рабочих процессов и расширенных возможностей логического мышления. Традиционные модели искусственного интеллекта часто ограничены объемом информации, которую они могут одновременно обработать, что препятствует решению задач, требующих понимания взаимосвязей в больших объемах данных. Окна длинного контекста позволяют моделям учитывать значительно больше информации, обеспечивая более глубокое понимание контекста и, как следствие, более точные и обоснованные ответы. Это особенно важно для приложений, где необходимо учитывать историю взаимодействия, понимать сложные документы или решать многоэтапные задачи, требующие отслеживания множества переменных. Повышение способности модели к обработке длинного контекста открывает путь к созданию интеллектуальных агентов, способных к более сложным и полезным взаимодействиям с пользователями и окружающим миром.
Анализ удержания пользователей играет ключевую роль в оценке долгосрочной эффективности и оптимизации производительности модели. Первоначальные данные, полученные в ходе наблюдения за базовыми группами пользователей, демонстрируют удержание на уровне приблизительно 40% к пятому месяцу использования. Это позволяет не только оценить фактическую ценность продукта для пользователей, но и выявить закономерности в их поведении, необходимые для дальнейшей настройки и улучшения модели. Постоянный мониторинг динамики удержания и анализ факторов, влияющих на неё, позволяют выстраивать стратегию развития, направленную на повышение лояльности пользователей и обеспечение устойчивого роста платформы.
Развитие устойчивой экосистемы вокруг моделей с открытыми весами представляется ключевым фактором для ускорения инноваций в области искусственного интеллекта и обеспечения широкого доступа к его преимуществам. Открытый доступ к базовым моделям позволяет исследователям, разработчикам и предпринимателям адаптировать и совершенствовать технологии, не ограничиваясь рамками закрытых систем. Это способствует появлению новых приложений и решений, адаптированных к специфическим потребностям различных отраслей и сообществ. Более того, создание открытой экосистемы стимулирует конкуренцию, снижает барьеры для входа на рынок и способствует демократизации доступа к передовым технологиям искусственного интеллекта, что в конечном итоге приносит пользу обществу в целом.
Исследование использования больших языковых моделей, представленное в данной работе, демонстрирует переход к агентному выводу и растущую роль моделей с открытым исходным кодом. Этот сдвиг подчеркивает, что системы неизбежно эволюционируют, адаптируясь к новым требованиям и условиям. Как однажды заметил Бертран Рассел: «Всякое великое предложение должно быть понято не буквально, а в духе». Подобно этому, анализ 100 триллионов токенов выявляет, что реальное использование моделей отличается от первоначальных ожиданий, и оценка должна быть более нюансированной. Стабильность метрик, как и стабильность любой системы, может быть лишь временной задержкой перед неизбежными изменениями, требующими переосмысления подходов к оценке и развитию.
Куда же дальше?
Настоящее исследование, подобно картографированию эрозии в ландшафте языковых моделей, обнажило тенденции, которые долгое время оставались скрытыми за завесой синтетических бенчмарков. Переход к агентному выводу — это не просто смена парадигмы, а признание того, что системы, стремящиеся к автономности, неизбежно эволюционируют в сторону непредсказуемости. Оценка производительности, основанная на статичных метриках, представляется все более условной — аптайм становится редкой фазой гармонии во времени, а не устойчивым состоянием.
Растущая роль открытых моделей не столько опровергает доминирование проприетарных решений, сколько демонстрирует закономерность: любое сложное построение, рано или поздно, подвергается децентрализации и адаптации. Однако, истинный вызов заключается не в увеличении вычислительных мощностей или создании новых архитектур, а в понимании того, как эти системы стареют. Технический долг, подобно эрозии, накапливается незаметно, и игнорирование этого процесса неизбежно приведет к потере устойчивости.
Будущие исследования должны сосредоточиться не на достижении новых рекордов производительности, а на разработке инструментов для мониторинга и управления энтропией в этих сложных системах. Необходимо перейти от оценки потенциала к анализу фактического износа, от оптимизации скорости к обеспечению долговечности. Иначе, вся эта гонка за совершенством окажется лишь иллюзией, а системы, подобные живым организмам, неизбежно столкнутся с неминуемым угасанием.
Оригинал статьи: https://arxiv.org/pdf/2601.10088.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-01-17 08:22