Автор: Денис Аветисян
Исследование предлагает гибридный подход к автоматическому обобщению финансовых документов, объединяя сильные стороны извлекающих и абстрактных методов.
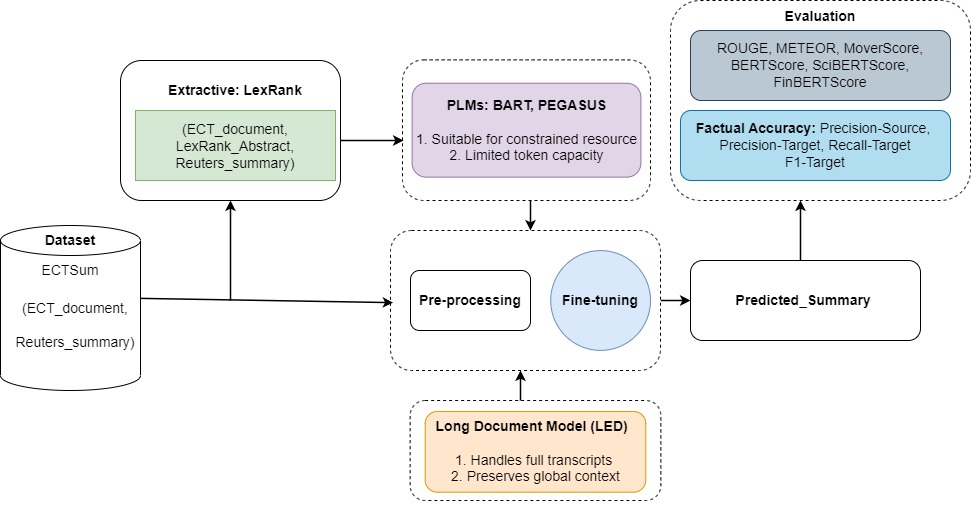
Применение моделей-трансформеров, включая Longformer, для повышения качества и достоверности обобщения длинных финансовых отчетов, таких как стенограммы телефонных конференций.
Анализ финансовых отчетов и коммуникаций, содержащих огромные объемы структурированной и неструктурированной информации, представляет собой сложную задачу, требующую значительных временных затрат и подверженную субъективным ошибкам. В данной работе, посвященной ‘Enhancing Business Analytics through Hybrid Summarization of Financial Reports’, предложен гибридный подход к автоматическому реферированию финансовых текстов, сочетающий в себе методы извлечения ключевых фрагментов и абстрактного перефразирования. Эксперименты с использованием моделей на основе трансформеров, включая Longformer, показали возможность достижения высокой точности и фактической согласованности рефератов, особенно при ограниченных вычислительных ресурсах. Может ли подобная технология стать ключевым инструментом для повышения эффективности финансового анализа и принятия обоснованных бизнес-решений?
Временные издержки: Вызовы финансового текстового реферирования
Анализ сложных финансовых документов, таких как стенограммы телефонных конференций по итогам квартала, имеет первостепенное значение для инвесторов, стремящихся оперативно оценивать положение компаний и принимать обоснованные решения. Однако, существующие методы автоматического реферирования зачастую сталкиваются с трудностями в обеспечении как точности, так и лаконичности. Автоматически созданные краткие обзоры нередко упускают из виду ключевые нюансы и тонкости, необходимые для глубокого понимания финансовой отчетности, либо же содержат неточности, способные ввести в заблуждение. В результате, инвесторам приходится тратить значительное время на ручную обработку больших объемов информации, что снижает эффективность инвестиционных стратегий и увеличивает риски.
Традиционные методы извлечения информации, хотя и отличаются простотой реализации, зачастую оказываются неспособны уловить тонкие нюансы и скрытые смыслы, содержащиеся в финансовых текстах. Они концентрируются на наиболее часто встречающихся фразах, упуская из виду критически важные детали и взаимосвязи. В то же время, подходы, основанные на полной абстракции и перефразировании, несут в себе риск внесения фактических ошибок и искажения исходного смысла. Даже незначительные неточности в финансовых сводках могут привести к серьезным последствиям для инвесторов, поэтому обеспечение достоверности и точности является первостепенной задачей при автоматической обработке финансовых документов.
Постоянно растущий объем финансовых данных, включая отчеты о доходах, новостные ленты и аналитические обзоры, создает острую необходимость в эффективных методах суммирования. Обработка длинных последовательностей текста без потери ключевой информации представляет собой сложную задачу для существующих алгоритмов. Простое сокращение объема данных часто приводит к упущению важных нюансов и взаимосвязей, что может негативно сказаться на принятии инвестиционных решений. Поэтому разработка новых подходов, способных эффективно обрабатывать большие объемы текста и сохранять при этом точность и информативность, является критически важной для современного финансового анализа и управления рисками. Успешные методы должны обеспечивать не только сжатие информации, но и выделение наиболее релевантных фактов и трендов, чтобы предоставить инвесторам и аналитикам четкую и лаконичную картину финансового положения компании.
Трансформеры и за их пределами: Новые горизонты реферирования
Трансформерные модели, такие как BART, PEGASUS и LED, стали мощным инструментом для абстрактного суммирования благодаря механизму самовнимания (self-attention). Этот механизм позволяет моделям учитывать взаимосвязи между удаленными участками текста, что особенно важно для обработки длинных документов и извлечения ключевой информации. В отличие от экстрактивных методов, которые просто выбирают существующие предложения, абстрактное суммирование предполагает генерацию нового текста, перефразирующего исходный материал, что требует более сложного понимания семантики и контекста. Само-внимание позволяет модели взвешивать вклад каждого слова в контексте всего документа, обеспечивая более точное и связное суммирование.
Трансформерные модели, демонстрирующие высокую степень беглости генерируемых рефератов, предъявляют значительные требования к вычислительным ресурсам. Несмотря на продвинутую архитектуру, эти модели подвержены неточностям, в особенности в отношении фактической корректности. Проблемы с сохранением фактологической точности проявляются в склонности к галлюцинациям и искажению исходной информации, что критично для применений, требующих высокой степени достоверности, например, в сфере финансовой аналитики и юридической документации. Необходимы дополнительные исследования и методы для повышения надежности и уменьшения вероятности генерации неверных или вводящих в заблуждение рефератов.
Применение тонко настроенных трансформаторных моделей, в особенности LED, демонстрирует улучшения в задачах суммирования финансовых транскриптов, однако наблюдается вариативность результатов. Согласно исследованию Mukherjee et al., модель достигла показателей ROUGE-1 в 0.467, а ROUGE-2 — 0.307. Данные метрики оценивают перекрытие униграмм и биграмм между сгенерированным и эталонным текстом, что позволяет количественно оценить качество суммирования. Важно отметить, что производительность может изменяться в зависимости от специфики финансовых данных и параметров настройки модели.
Оценка качества: Метрики и вызовы объективности
Традиционные метрики оценки качества суммаризации, такие как ROUGE и METEOR, основаны на измерении лексического совпадения между сгенерированным и эталонным суммаризациями. Однако, этот подход имеет существенные ограничения, поскольку не учитывает семантическую близость и фактическую точность. Метрики, оценивающие лишь совпадение слов или n-грамм, могут выдавать высокие оценки суммаризациям, которые грамматически корректны, но содержат неверную или нерелевантную информацию, или, наоборот, занижать оценки семантически эквивалентных, но лексически отличающихся суммаризаций. Это связано с тем, что они не способны понимать значение текста и не учитывают синонимию, перефразирование и другие лингвистические явления, влияющие на смысл.
Метрики BERTScore и MoverScore, в отличие от традиционных, используют контекстные векторные представления (embeddings) слов и предложений для оценки семантической близости между сгенеризированным и эталонным резюме. Вместо простого подсчета совпадений слов, они учитывают контекст, в котором эти слова употребляются, что позволяет более точно оценить, насколько хорошо резюме передает смысл исходного текста. Это достигается путем сравнения векторных представлений слов и предложений, полученных с помощью предварительно обученных языковых моделей, таких как BERT. Таким образом, эти метрики способны выявлять семантическое сходство даже при отсутствии лексического совпадения, обеспечивая более нюансированную и адекватную оценку качества резюмирования.
Для оценки качества суммаризации специализированных текстов, таких как финансовые отчеты и научные статьи, применяются метрики FinBERTScore и SciBERTScore, являющиеся адаптациями BERTScore. В ходе тестирования BERTScore показал наивысшие общие результаты, в то время как модель LED продемонстрировала высокую эффективность по показателям Precision-source и Recall-target, что указывает на ее способность точно извлекать информацию из исходного текста и адекватно ее воспроизводить в сжатом виде. Несмотря на улучшенную релевантность к специализированным текстам, даже эти метрики не являются абсолютно совершенными и могут давать неточные оценки в сложных случаях.
Наборы данных и погоня за фактической согласованностью
Набор данных ECTSum представляет собой ценный ресурс для обучения и оценки моделей суммаризации финансовых текстов. Он состоит из расшифровок телефонных конференций по итогам квартальных отчетов (earnings calls) и соответствующих экспертных резюме. Набор данных включает в себя как исходные тексты, представляющие собой стенограммы, так и эталонные сводки, созданные финансовыми аналитиками. Это позволяет разработчикам обучать модели суммаризации и оценивать их способность извлекать ключевую информацию и генерировать краткие, но точные обзоры финансовых результатов компании. ECTSum содержит данные по различным компаниям и отраслям, что обеспечивает разнообразие и обобщающую способность обученных моделей.
Одной из ключевых проблем при создании систем автоматического реферирования финансовых текстов является обеспечение фактической согласованности — предотвращение генерации неподтвержденной или неточной информации, известной как «галлюцинации». В контексте финансовых отчетов и транскриптов, даже незначительные фактические ошибки могут привести к серьезным последствиям, включая неправильные инвестиционные решения или юридические риски. Поэтому, разработка методов, гарантирующих соответствие сгенерированных рефератов исходным данным, является критически важной задачей для повышения надежности и доверия к таким системам. Особое внимание уделяется предотвращению добавления информации, отсутствующей в исходном тексте, или искажению существующих фактов.
Оценка качества систем финансового реферирования, таких как суммирование стенограмм телефонных конференций о финансовых результатах, требует применения специализированных наборов данных, например ECTSum. Для построения надежных систем необходимо использовать метрики, ориентированные на фактическую точность. В ходе исследований модель PEGASUS-large продемонстрировала наивысший результат по метрике F1-target, что свидетельствует о ее высокой эффективности в генерации точных и фактических рефератов. Данный показатель отражает способность модели корректно извлекать и представлять ключевую информацию из исходных текстов, минимизируя риск генерации ложных или неподтвержденных утверждений.
Будущее автоматизированного реферирования: Влияние и возможности
Автоматизированное суммирование финансовых текстов обладает значительным потенциалом для улучшения процесса принятия инвестиционных решений. Благодаря возможности быстрого извлечения ключевой информации из отчётов о доходах и конференц-звонков, инвесторы получают возможность оперативно оценивать финансовое состояние компаний и выявлять важные тенденции. Это позволяет сократить время, затрачиваемое на анализ больших объемов данных, и повысить эффективность инвестиционных стратегий. Более того, подобная автоматизация открывает возможности для выявления скрытых взаимосвязей и факторов, которые могли бы остаться незамеченными при ручном анализе, что способствует принятию более обоснованных и перспективных решений.
Автоматизированное суммирование финансовых текстов способно значительно упростить процессы подготовки нормативной отчетности и соблюдения регуляторных требований. Внедрение подобных технологий позволит сократить временные и финансовые затраты, связанные с обработкой больших объемов документации, и повысить прозрачность отчетности для контролирующих органов. Уменьшение нагрузки на специалистов, занимающихся комплаенсом, позволит им сосредоточиться на более сложных задачах анализа и стратегического планирования. Более того, автоматизация снижает вероятность ошибок, возникающих при ручной обработке данных, что способствует повышению надежности и точности предоставляемой информации, что особенно важно в условиях ужесточения требований к финансовой отчетности.
Перспективные исследования в области автоматического суммирования финансовых текстов направлены на создание более устойчивых и фактологически точных моделей. Особое внимание уделяется интеграции специализированных знаний, относящихся к финансовой сфере, и развитию способностей к логическому выводу. Это позволит не просто извлекать ключевую информацию из отчетов и конференций, но и устанавливать причинно-следственные связи, выявлять потенциальные риски и возможности, а также генерировать осмысленные и обоснованные выводы, что значительно повысит качество и надежность автоматизированного анализа финансовых данных.
Исследование, посвященное гибридному суммированию финансовых отчетов, демонстрирует стремление к адаптации систем к постоянно меняющимся требованиям времени. Как отмечал Анри Пуанкаре, «Чистая математика — это логическая игра, в которой принимаются условные правила, а истина не является целью». В данном контексте, ‘условные правила’ — это алгоритмы и модели, используемые для обработки больших объемов данных, а ‘истина’ — это максимально точное и последовательное представление финансовой информации. Работа над обеспечением фактической согласованности, особенно при использовании абстрактивных моделей, подчеркивает необходимость постоянной оценки и совершенствования систем, чтобы они не теряли своей актуальности и достоверности с течением времени. Ведь, как и в математике, в анализе финансовых данных важна не только формальная точность, но и соответствие реальности.
Что дальше?
Представленная работа, исследуя гибридные подходы к суммированию финансовых отчетов, неизбежно наталкивается на фундаментальное ограничение: любая система, даже самая изощренная, лишь отражает, но не предотвращает течение времени. Стремление к идеальной точности суммирования — благородно, но, возможно, и тщетно. Ведь финансовые документы, как и сама реальность, содержат в себе неопределенность, нюансы, которые любая модель неизбежно упрощает. Важнее не скорость, с которой извлекается информация, а глубина понимания ее контекста.
Будущие исследования, вероятно, сосредоточатся не на совершенствовании алгоритмов, а на создании систем, способных учиться на своих ошибках, распознавать и сигнализировать о потенциальных искажениях. Мудрые системы не борются с энтропией — они учатся дышать вместе с ней. Вместо того, чтобы пытаться ускорить процесс анализа, возможно, стоит больше внимания уделять долгосрочному мониторингу и оценке надежности полученных результатов.
Иногда наблюдение — единственная форма участия. Развитие моделей, способных не просто суммировать данные, но и выявлять скрытые тенденции, предсказывать риски и оценивать вероятность различных сценариев, представляется более перспективным направлением, чем погоня за абсолютной точностью. Ведь в конечном итоге, ценность информации заключается не в ее объеме, а в ее способности помочь принимать взвешенные решения.
Оригинал статьи: https://arxiv.org/pdf/2601.09729.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-01-17 03:18