Автор: Денис Аветисян
Новый подход позволяет повысить надежность систем обнаружения аномалий, эффективно отсеивая ошибочные данные в обучающей выборке.

Предложена методика Adaptive and Aggressive Rejection (AAR), сочетающая модифицированный Z-критерий и Гауссовскую смесь для динамического исключения выбросов и повышения устойчивости к зашумленным данным.
Обнаружение аномалий часто затруднено наличием загрязненных данных в обучающей выборке, поскольку стандартные модели предполагают обучение на чисто нормальных данных. В работе, посвященной ‘Anomaly Detection with Adaptive and Aggressive Rejection for Contaminated Training Data’, предложен новый метод Adaptive and Aggressive Rejection (AAR), динамически исключающий аномалии на основе модифицированного z-оценщика и порогов, построенных на основе Гауссовой смеси. Эксперименты на различных наборах данных демонстрируют, что AAR превосходит современные методы, обеспечивая повышенную устойчивость к загрязнению данных. Возможно ли, что данная методика станет ключевым элементом в системах обнаружения аномалий в критически важных областях, таких как безопасность и здравоохранение?
Поиск Исключений: Фундамент Анализа
В основе множества аналитических задач лежит способность выявлять аномалии — данные, существенно отклоняющиеся от общепринятой нормы. Этот процесс поиска необычного является фундаментальным для различных областей, начиная от обнаружения мошеннических транзакций и заканчивая диагностикой технических неисправностей. Выявление таких отклонений позволяет своевременно реагировать на потенциальные проблемы или, наоборот, находить ценные инсайты, скрытые в массиве данных. Эффективность таких систем напрямую зависит от точности определения границ «нормы», что представляет собой сложную задачу, особенно при работе с многомерными и динамически изменяющимися данными. Именно способность к выявлению аномалий позволяет системам адаптивно реагировать на изменяющиеся условия и обеспечивать более надежные и точные результаты анализа.
Реальные наборы данных редко бывают идеальными; чаще всего они представляют собой “загрязненные данные”, содержащие как нормальные экземпляры, так и истинные аномалии, что значительно усложняет задачу их выявления. Это означает, что алгоритмы обнаружения аномалий должны уметь различать отклонения, которые являются подлинными сигналами о необычном явлении, от тех, которые являются просто шумом или следствием естественной изменчивости данных. Проблема усугубляется тем, что количество аномалий обычно значительно меньше, чем количество нормальных данных, что требует от алгоритмов высокой чувствительности и способности к обнаружению редких событий. Разработка эффективных методов для работы с такими «загрязненными» данными является ключевой задачей в различных областях, от обнаружения мошенничества и кибербезопасности до медицинской диагностики и контроля качества.
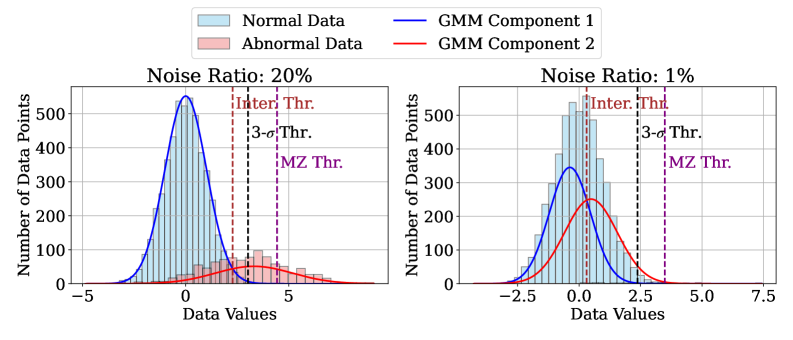
Количественная Оценка Отклонений: Оценка Аномалий
В основе обнаружения аномалий лежит показатель, называемый “Оценкой аномалии” (Anomaly Score), представляющий собой численную метрику, предназначенную для количественной оценки степени отклонения от ожидаемого поведения. Эта оценка позволяет ранжировать наблюдения по степени их необычности; чем выше значение оценки, тем более вероятно, что соответствующая точка данных является аномалией. В практических приложениях, порог для определения аномалии устанавливается на основе анализа распределения оценок аномалий и требований конкретной задачи. Таким образом, оценка аномалии служит ключевым инструментом для автоматизированного выявления и классификации нетипичных событий или объектов в данных.
Оценка аномалий часто базируется на непараметрических методах, таких как оценка плотности ядра (KDE). KDE позволяет оценить распределение вероятностей данных без предположений о его форме, используя ядра — функции, определяющие вес каждой точки данных при оценке плотности в определенной точке пространства признаков. Плотность оценивается как взвешенная сумма ядер, центрированных в каждой точке данных. Более низкая плотность вероятности в определенной точке указывает на отклонение от типичного поведения и, следовательно, может служить основой для расчета аномального балла. Выбор ядра и ширины полосы пропускания ($h$) оказывает существенное влияние на точность оценки и требует тщательной настройки.
Автокодировщики (AE) представляют собой нейронные сети, обученные сжимать входные данные в представление меньшей размерности, а затем восстанавливать их из этого сжатого представления. В контексте обнаружения аномалий, AE обучаются на нормальных данных, что позволяет им эффективно реконструировать типичные входные значения. Аномалии, отклоняющиеся от обученных шаблонов, приводят к значительно более высокой ошибке реконструкции, поскольку сеть не способна адекватно их восстановить. Величина ошибки реконструкции, выраженная как $E = ||x — \hat{x}||$, где $x$ — входные данные, а $\hat{x}$ — восстановленные данные, используется в качестве оценки аномалии — чем выше ошибка, тем более вероятно, что входные данные являются аномальными.

Устойчивость и Уточнение: Повышение Точности Обнаружения
Для повышения надежности обнаружения аномалий в условиях загрязненных данных, применение устойчивых методов является критически важным. Загрязнение данных, представляющее собой наличие в обучающей выборке выбросов или ошибочных значений, может существенно исказить параметры модели и снизить точность обнаружения истинных аномалий. Устойчивые методы, такие как использование робастных функций потерь или алгоритмов, менее чувствительных к выбросам, позволяют минимизировать влияние загрязненных данных на процесс обучения и, следовательно, повысить общую надежность системы обнаружения аномалий. Это особенно важно в практических приложениях, где данные часто содержат ошибки или неполную информацию.
Функции псевдо-Хабера $L_{\delta}(x) = \begin{cases} \frac{1}{2}x^2, & |x| \le \delta \\ \delta(|x| — \frac{1}{2}\delta), & |x| > \delta \end{cases}$ используются в качестве функции потерь для снижения влияния выбросов при обучении моделей обнаружения аномалий. В отличие от квадратичной функции потерь, которая линейно увеличивается с увеличением ошибки, псевдо-Хабер имеет более медленный рост для больших ошибок, что ограничивает вклад выбросов в общий градиент и, следовательно, стабилизирует процесс обучения. Это приводит к более надежным оценкам аномалий и снижает чувствительность модели к зашумленным данным.
Точная оценка доли аномалий в наборе данных, известная как ‘Contamination Ratio Estimation’ (оценка коэффициента загрязнения), критически важна для корректной установки порогов обнаружения. Неверная оценка может привести к ложноположительным или ложноотрицательным результатам. Низкая оценка приведет к повышенной чувствительности и увеличению числа ложных срабатываний, в то время как завышенная оценка снизит чувствительность и приведет к пропуску реальных аномалий. Методы оценки коэффициента загрязнения включают в себя статистические подходы, основанные на анализе распределения данных, а также алгоритмы машинного обучения, направленные на идентификацию и количественную оценку аномальных экземпляров в наборе данных. Правильно определенный коэффициент загрязнения позволяет оптимизировать пороги обнаружения и максимизировать эффективность системы аномального обнаружения.
Предложенный нами фреймворк Adaptive and Aggressive Rejection (AAR) демонстрирует среднее улучшение метрики AUROC на 0.041 при тестировании на различных наборах данных. Достижение этого результата обусловлено динамической адаптацией политик отбраковки, позволяющей варьировать критерии исключения потенциальных аномалий. AAR использует комбинацию методов жесткого (hard rejection), при котором экземпляры однозначно исключаются, и мягкого (soft rejection), при котором вероятность принадлежности к аномалии снижается, что позволяет более гибко настраивать процесс обнаружения аномалий и повышать общую точность.
За Пределами Обнаружения: Расширение Горизонтов Аномалий
Принципы обнаружения аномалий выходят далеко за рамки простого выявления отклонений, являясь основой для широкого спектра приложений в различных областях. От систем обнаружения мошеннических операций, где выявление необычных транзакций критически важно для защиты финансовых ресурсов, до предиктивной аналитики в сфере технического обслуживания, где аномалии в показателях оборудования предвещают потенциальные поломки и позволяют предотвратить дорогостоящие простои — возможности применения этих методов огромны. Способность алгоритмов к выявлению нетипичного поведения находит применение в мониторинге сетевой безопасности, где аномальный трафик может указывать на кибератаки, а также в контроле качества продукции, где отклонения от нормы сигнализируют о дефектах. Таким образом, обнаружение аномалий становится ключевым элементом в обеспечении надежности, безопасности и эффективности различных систем и процессов.
Алгоритмы, такие как Одноклассовая машина опорных векторов (OC-SVM), представляют собой мощные инструменты для изучения границ нормального поведения в данных. Вместо поиска признаков, характерных для аномалий, OC-SVM фокусируется на моделировании типичных данных, создавая своего рода “профиль” нормальности. Этот подход особенно эффективен в ситуациях, когда аномалии редки или плохо определены, поскольку алгоритм не требует примеров отклонений для обучения. По сути, OC-SVM строит границу, отделяющую нормальные данные от всего остального, позволяя эффективно выявлять любые отклонения от установленного шаблона в сложных и многомерных наборах данных. Такая методика находит применение в самых разных областях, от обнаружения мошеннических операций до прогнозирования отказов оборудования, обеспечивая возможность оперативного реагирования на нетипичные ситуации.
Исследования на табличных данных продемонстрировали превосходство фреймворка AAR над альтернативными методами обнаружения аномалий, такими как AE, MemAE и DSVDD. В частности, AAR показал улучшение в 0.34, 0.28 и 0.32 соответственно по метрике AUROC (Area Under the Receiver Operating Characteristic curve). Это свидетельствует о более высокой способности AAR точно идентифицировать отклонения от нормального поведения в данных, что критически важно для приложений, требующих надежного обнаружения аномалий, например, в системах предотвращения мошенничества или мониторинге состояния оборудования. Повышенная точность, продемонстрированная AAR, позволяет снизить количество ложных срабатываний и повысить эффективность анализа данных.
Более глубокое освоение методов выявления аномалий открывает возможности для значительного улучшения качества данных, используемых в различных областях. Понимание принципов работы алгоритмов, таких как OC-SVM, позволяет не только идентифицировать отклонения от нормы, но и выявлять потенциальные ошибки или неточности в исходных данных, что способствует их очистке и повышению надежности. В результате, аналитические выводы, основанные на таких данных, становятся более достоверными и точными, предоставляя прочную основу для принятия обоснованных решений. Это особенно важно в критически важных областях, где даже незначительные погрешности могут привести к серьезным последствиям, а надежная информация является ключевым фактором успеха.
Исследование демонстрирует, что стремление к совершенству алгоритмов обнаружения аномалий часто упирается в проблему загрязненных данных. Предлагаемый подход, Adaptive and Aggressive Rejection (AAR), акцентирует внимание на динамической адаптации к этим неблагоприятным условиям, что соответствует философии поиска истины через испытания. Как однажды заметил Линус Торвальдс: «Большинство хороших программ написаны не потому, что они были спроектированы, а потому, что они были написаны, протестированы и переписаны». Этот принцип применим и к разработке robust алгоритмов — постоянное тестирование и адаптация к реальным, часто зашумленным, данным позволяют создать систему, способную эффективно выделять аномалии даже в условиях высокой степени загрязнения обучающей выборки.
Куда Далее?
Предложенный подход, основанный на адаптивном и агрессивном отбраковании, безусловно, открывает новые возможности в обнаружении аномалий, особенно в условиях загрязненных данных. Однако, само понятие «загрязнения» требует дальнейшего осмысления. Что, если «загрязнение» — это не ошибка, а проявление скрытых закономерностей, которые текущие модели просто не способны уловить? Необходимо исследовать, как AAR можно модифицировать для сохранения информации, содержащейся в отбракованных данных, а не просто для её игнорирования.
Следующим шагом представляется переход от статической оценки порога отбраковки к динамической, учитывающей не только статистические характеристики данных, но и контекст задачи. Необходимо разработать метрики, позволяющие оценить «стоимость» ложного отбраковки, сопоставимую со «стоимостью» ложного срабатывания. Возможно, в будущем, алгоритмы обнаружения аномалий будут строиться на принципах минимизации общей стоимости ошибки, а не просто на максимизации точности.
В конечном счете, истинное испытание для AAR и подобных подходов — это столкновение с данными, которые намеренно разработаны для обмана алгоритмов. Создание «состязательных» наборов данных, имитирующих реальные атаки на системы обнаружения аномалий, позволит проверить устойчивость предложенного метода и выявить его слабые места. Ведь, как известно, любое правило создано для того, чтобы его нарушали.
Оригинал статьи: https://arxiv.org/pdf/2511.21378.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2025-11-28 18:11