Автор: Денис Аветисян
Новое исследование предлагает метод оптимизации процесса рассуждений в больших языковых моделях, позволяя им самостоятельно определять оптимальную длину цепочки рассуждений.
Применение обучения с подкреплением для адаптивной настройки длины цепочки рассуждений и повышения эффективности работы языковых моделей.
Несмотря на успехи языковых моделей в решении сложных задач, их способность к эффективному логическому выводу часто ограничивается избыточностью и вычислительными затратами. В работе ‘Learning When to Stop: Adaptive Latent Reasoning via Reinforcement Learning’ предлагается новый подход — адаптивное латентное рассуждение, оптимизируемое с помощью обучения с подкреплением. Данный метод позволяет сократить длину процесса рассуждения без потери точности, тем самым снижая вычислительную нагрузку и повышая эффективность моделей. Возможно ли дальнейшее развитие этого подхода для создания еще более компактных и производительных систем искусственного интеллекта, способных к глубокому и эффективному логическому выводу?
Предел Традиционного Рассуждения: Когда Теория Встречает Реальность
Несмотря на значительный прогресс, достигнутый благодаря методу «Chain-of-Thought» в развитии языковых моделей, данный подход часто характеризуется чрезмерной длиной генерируемых рассуждений и, как следствие, высокой вычислительной стоимостью. Каждый шаг логической цепочки требует дополнительных ресурсов, что существенно замедляет процесс обработки информации и ограничивает возможности применения модели в условиях ограниченных вычислительных мощностей. По сути, увеличение сложности рассуждений не всегда приводит к пропорциональному улучшению результатов, а наоборот, может приводить к снижению эффективности и увеличению времени отклика, особенно при решении масштабных задач. Таким образом, поиск более компактных и экономичных методов рассуждений становится ключевой задачей для дальнейшего развития искусственного интеллекта.
Попытки улучшить производительность языковых моделей путём простого увеличения масштаба традиционных методов рассуждений, таких как цепочка мыслей, неизбежно сталкиваются с законом убывающей отдачи. Несмотря на первоначальный прогресс, дальнейшее увеличение объёма данных и вычислительных ресурсов приводит к всё менее значимым улучшениям в решении сложных задач. Это связано с тем, что традиционные архитектуры не способны эффективно обрабатывать растущую сложность и неоднозначность информации. В результате, возникает потребность в принципиально новых подходах к организации рассуждений, которые бы обеспечивали более высокую эффективность и масштабируемость, позволяя моделям решать задачи, недоступные при использовании существующих методов. Исследования в области эффективных архитектур рассуждений направлены на создание систем, способных извлекать максимум информации из минимального количества данных и вычислений, открывая путь к созданию действительно интеллектуальных систем.
Современные методы искусственного интеллекта, несмотря на значительный прогресс, испытывают трудности при решении сложных задач, требующих глубокого и нюансированного рассуждения. Это ограничение проявляется в неспособности систем адекватно обрабатывать неоднозначную информацию, проводить аналогии, требующие контекстуального понимания, и выводить логические заключения, выходящие за рамки формальных правил. Отсутствие подобной способности к тонкому анализу препятствует развитию действительно интеллектуальных систем, способных к творческому решению проблем и адаптации к новым, непредсказуемым ситуациям. В результате, существующие модели часто демонстрируют поверхностное понимание, опираясь на статистические закономерности, а не на истинное осмысление проблемы, что ставит под вопрос возможность создания полноценного искусственного интеллекта, способного конкурировать с человеческим разумом.

Скрытое Рассуждение: Экономия Ресурсов, Сохранение Точности
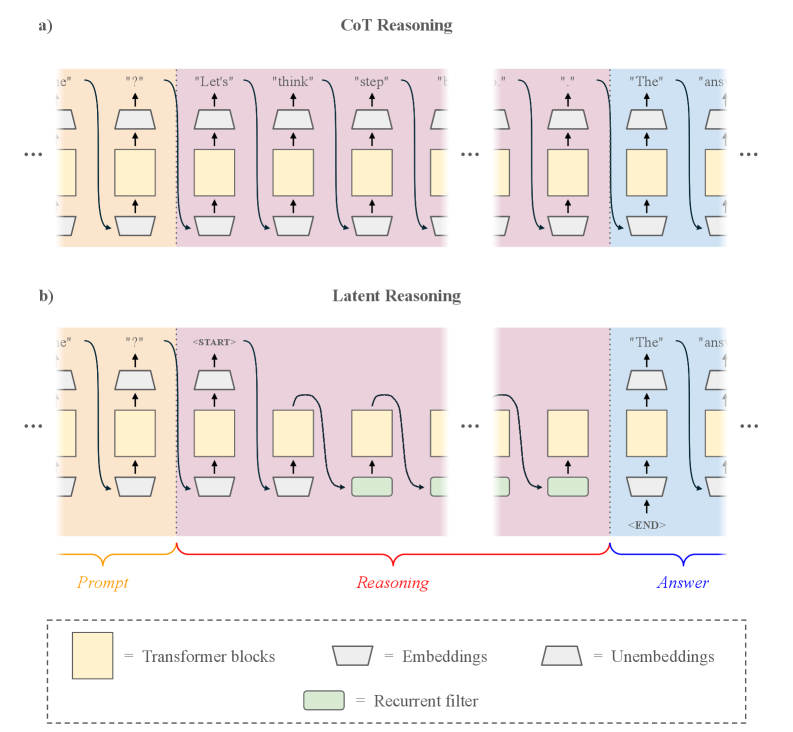
Метод «скрытого рассуждения» (Latent Reasoning) напрямую использует внутренние состояния (hidden states) архитектуры Transformer, что позволяет избежать необходимости генерировать многословные промежуточные шаги рассуждений. Вместо явного построения последовательности действий, решение задачи формируется внутри модели посредством манипуляций с этими внутренними представлениями. Такой подход позволяет обойти этап текстовой генерации промежуточных выводов, что существенно снижает вычислительные затраты и ускоряет процесс рассуждений, не снижая при этом точность результатов. Внутренние состояния модели выступают как «рабочее пространство», где задача решается посредством преобразования векторных представлений данных.
Метод Latent Reasoning значительно снижает вычислительные затраты и повышает скорость рассуждений за счет работы непосредственно с внутренним представлением модели — её скрытыми состояниями. В ходе экспериментов зафиксировано уменьшение количества токенов, используемых для рассуждений, на 52.94% без потери точности. Это достигается за счет отказа от генерации многословных промежуточных шагов, характерных для традиционных подходов, и переходом к неявному внутреннему вычислению, что позволяет более эффективно использовать ресурсы и ускорить процесс принятия решений.
Традиционные методы логического вывода в больших языковых моделях (LLM) основаны на последовательной генерации промежуточных шагов, что требует значительных вычислительных ресурсов и времени. Подход скрытого рассуждения (Latent Reasoning) кардинально меняет этот процесс, перенося вычисления из области явной генерации текста во внутреннее представление модели. Вместо поэтапного формирования текстовых объяснений, решение задачи происходит в скрытых слоях Transformer, используя уже существующие активации и веса. Это позволяет существенно сократить объем генерируемых токенов, сохраняя при этом точность и скорость рассуждений, поскольку большая часть вычислений выполняется неявно внутри модели, а не через явное формирование и обработку текста.

Оптимизация Скрытого Рассуждения: Когда Усилия Приносят Плоды
Предварительное обучение с учителем обеспечивает надежную основу для скрытого рассуждения, однако для достижения оптимальной производительности требуется дальнейшая доработка. Изначальная настройка модели на размеченных данных позволяет ей усвоить базовые принципы логического вывода, но недостаточно для решения сложных задач, требующих многоступенчатого анализа. Для улучшения способности модели к абстрактному мышлению и эффективному использованию внутренних представлений необходимы дополнительные методы обучения, такие как обучение с подкреплением или применение специализированных штрафов, ограничивающих избыточную длину цепочки рассуждений.
Обучение с подкреплением, в частности, с использованием алгоритмов, таких как Group Relative Policy Optimization (GRPO), позволяет оптимизировать внутренний процесс рассуждений модели. В отличие от традиционного обучения с учителем, GRPO позволяет модели самостоятельно исследовать различные стратегии рассуждений и получать вознаграждение за корректные и эффективные шаги. Это достигается путем определения функции вознаграждения, которая оценивает качество цепочки рассуждений, и последующей оптимизации политики модели для максимизации этого вознаграждения. Алгоритм GRPO способствует формированию более надежных и последовательных логических выводов, улучшая общую производительность модели в задачах, требующих латентных рассуждений.
Применение методов, таких как штрафы за длину рассуждений и THINKPRUNE, направлено на сокращение избыточности в процессе логического вывода, что способствует повышению эффективности и производительности модели. В ходе экспериментов было зафиксировано снижение количества токенов, используемых для рассуждений, на 70.58%, при этом точность модели увеличилась на 0.38%. Данные методы активно ограничивают чрезмерно длинные последовательности рассуждений, оптимизируя использование вычислительных ресурсов и ускоряя процесс принятия решений.

Усиление Скрытого Рассуждения: Передача Знаний и Адаптивные Стратегии
Процесс дистилляции знаний позволяет переносить навыки рассуждений из больших, сложных моделей в более компактные и эффективные. Этот подход использует такие методы, как Meaned Reasoning Loss и Intermediate Block Loss, которые фокусируются на передаче не только конечного результата, но и промежуточных шагов рассуждений. Meaned Reasoning Loss, например, стремится минимизировать разницу между логическими выводами большой и маленькой моделей, а Intermediate Block Loss акцентирует внимание на согласованности промежуточных представлений. Таким образом, небольшая модель учится не просто имитировать ответ, но и воспроизводить процесс мышления, что позволяет ей решать задачи, требующие сложных логических выводов, с большей эффективностью и меньшими вычислительными затратами.
Методики CODI и COCONUT представляют собой дальнейшее усовершенствование процесса передачи знаний от больших моделей к более компактным. CODI использует самодистилляцию, при которой модель обучается, имитируя собственные более точные прогнозы, полученные на предыдущих этапах обучения, что позволяет ей самостоятельно совершенствовать процесс рассуждений. В свою очередь, COCONUT применяет поэтапное обучение (staged curriculum learning), представляя задачи в порядке возрастающей сложности. Такой подход позволяет модели постепенно осваивать сложные концепции, начиная с более простых примеров, что значительно повышает эффективность обучения и общую производительность. Обе методики направлены на оптимизацию процесса дистилляции знаний, позволяя создавать более эффективные и компактные модели без существенной потери в точности.
Адаптивное скрытое рассуждение представляет собой инновационный подход, позволяющий модели динамически определять момент завершения процесса рассуждения, избегая избыточных вычислений. Такой механизм не только повышает эффективность, но и демонстрирует впечатляющие результаты: в ходе тестирования достигнута точность в $42.6\%$ при одновременном сокращении количества токенов на $52.94\%$. Этот показатель служит важной точкой сравнения с точностью $43.2\%$, полученной при использовании метода CODI, подтверждая перспективность адаптивного подхода к оптимизации процессов рассуждения в задачах искусственного интеллекта.
![Схема сопоставляет дистилляцию знаний CODI с функцией потерь усредненного рассуждения, где ℒCODI соответствует ℒKD, используемой в работе [shen2025codi].](https://arxiv.org/html/2511.21581v1/x4.png)
Будущее Скрытого Рассуждения: К Масштабируемым и Интеллектуальным Системам
Интеграция рекуррентных фильтров с латентным рассуждением представляет собой перспективный подход к улучшению обработки внутренних состояний системы и, как следствие, повышению качества самого процесса рассуждения. В традиционных моделях латентного рассуждения информация о предыдущих шагах обработки часто теряется, что ограничивает способность системы к последовательному и контекстуально-зависимому анализу. Рекуррентные фильтры, в свою очередь, позволяют сохранять и использовать информацию из предыдущих состояний, создавая своего рода “память” для системы. Это особенно важно при решении сложных задач, требующих учета множества взаимосвязанных факторов и долгосрочного планирования. Такой симбиоз латентного рассуждения и рекуррентных фильтров позволяет модели не только выводить логические заключения, но и учитывать историю своих действий, что существенно повышает её надежность и эффективность в динамически меняющихся условиях. Предварительные исследования показывают, что данная архитектура демонстрирует значительное улучшение в задачах, требующих сложных умозаключений и адаптации к новым данным.
Внедрение специальных токенов в модели латентного рассуждения открывает новые возможности для точного управления процессом логических выводов. Данный подход позволяет не просто генерировать ответы, но и направлять ход мыслей модели, определяя, какие аспекты информации должны быть учтены и как они должны быть сопоставлены. Использование этих токенов функционирует как своего рода «сигналы управления», активирующие или подавляющие определенные рассуждения, что существенно повышает контролируемость и интерпретируемость модели. В результате, появляется возможность не только получать более точные и обоснованные ответы, но и понимать, каким образом модель пришла к этим выводам, что особенно важно для критически важных приложений, требующих прозрачности и надежности.
Дальнейшие исследования в области адаптивных стратегий и дистилляции знаний открывают перспективные пути к созданию более эффективных и масштабируемых систем рассуждений. Адаптивные стратегии позволяют системам динамически корректировать свои методы в зависимости от сложности задачи и доступных ресурсов, что способствует оптимизации процесса рассуждений. В свою очередь, дистилляция знаний предполагает передачу опыта от больших, сложных моделей к более компактным и быстрым, сохраняя при этом высокую точность. Сочетание этих подходов позволяет создавать системы, способные обрабатывать большие объемы информации и решать сложные задачи с минимальными вычислительными затратами, что особенно важно для применения в реальных условиях и для создания искусственного интеллекта, способного к непрерывному обучению и адаптации к изменяющейся среде.

Исследование адаптивной скрытой логики, представленное в статье, неизбежно напоминает о вечной борьбе между теоретической элегантностью и суровой реальностью продакшена. Авторы стремятся оптимизировать длину рассуждений в больших языковых моделях, используя обучение с подкреплением, что, по сути, является попыткой обуздать вычислительную сложность. Как метко заметил Роберт Тарьян: «Любая абстракция умирает от продакшена». Эта фраза словно эпитафия всем изящным алгоритмам, сталкивающимся с потоком реальных данных. Статья демонстрирует, что даже самые передовые методы, такие как обучение с подкреплением, направлены на то, чтобы сделать процесс рассуждений более эффективным, а не бесконечным, признавая, что ресурсы всегда ограничены.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал адаптивного логического вывода в больших языковых моделях. Однако, оптимизация длины цепочки рассуждений — это лишь одна грань проблемы. Скорее всего, практика продемонстрирует, что любое «умное» сокращение рано или поздно потребует дополнительных ресурсов для восстановления утерянного контекста. Архитектура, стремящаяся к эффективности, неизбежно столкнется с необходимостью компромиссов, которые придется оплачивать вычислительным временем.
Наиболее интересным представляется не столько сам алгоритм адаптации, сколько осознание того, что фиксированная длина рассуждений — это искусственное ограничение. Попытки «научить» модель останавливаться — это, по сути, попытки заставить ее признать собственную некомпетентность. В конечном итоге, вопрос в том, как создать систему, способную оценивать не только результат рассуждений, но и уверенность в этом результате.
Вероятно, следующая волна исследований будет направлена на разработку более сложных функций вознаграждения, учитывающих не только точность ответа, но и вычислительные затраты, а также степень «удивления» модели в процессе рассуждений. Иначе говоря, мы не учим модель мыслить — мы учим ее имитировать экономию.
Оригинал статьи: https://arxiv.org/pdf/2511.21581.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2025-11-28 09:47