Автор: Денис Аветисян
Новое исследование показывает, как методы, разработанные для объяснения принципов работы языковых моделей, могут быть успешно применены для анализа внутренних механизмов трансформеров, используемых для обработки временных рядов.

Исследование применяет методы механической интерпретируемости, включая патчинг активаций и анализ внимания, для выявления ключевых причинно-следственных связей и скрытых признаков в моделях временных рядов.
Несмотря на выдающиеся успехи трансформерных моделей в задачах классификации временных рядов, понимание внутренних механизмов их принятия решений остается сложной задачей. В работе ‘Mechanistic Interpretability for Transformer-based Time Series Classification’ предложен подход, адаптирующий методы механической интерпретируемости, разработанные для обработки естественного языка, к архитектурам трансформеров, предназначенным для анализа временных рядов. Исследование выявляет ключевые причинно-следственные связи внутри моделей, демонстрируя, как информация распространяется через различные головы внимания и временные шаги. Могут ли эти методы не только пролить свет на внутреннюю работу трансформеров, но и способствовать созданию более надежных и интерпретируемых моделей для анализа временных рядов?
Раскрывая Временные Закономерности: Необходимость Понимания
Трансформеры для анализа временных рядов демонстрируют впечатляющую эффективность в прогнозировании и выявлении закономерностей, однако зачастую функционируют как непрозрачные “черные ящики”. Эта особенность существенно ограничивает возможности доверия к результатам и последующей доработки моделей. Невозможность понять, какие именно факторы и на каких временных отрезках оказывают наибольшее влияние на предсказания, создает серьезные препятствия для применения в критически важных областях, таких как медицина, финансы и прогнозирование климата. В отличие от более простых моделей, где логика принятия решений относительно понятна, сложность архитектуры трансформеров затрудняет интерпретацию и выявление ключевых механизмов, лежащих в основе их работы, что подчеркивает необходимость разработки методов, обеспечивающих прозрачность и объяснимость.
Для надежного применения моделей временных рядов, особенно в критически важных областях, таких как здравоохранение или финансовый анализ, недостаточно просто получить точный прогноз. Крайне важно понимать, каким образом модель пришла к этому заключению. Отсутствие прозрачности в процессе принятия решений может привести к недоверию и затруднить выявление потенциальных ошибок или предвзятостей. В ситуациях, где последствия неверных прогнозов могут быть серьезными, необходимо не просто видеть результат, но и отслеживать логику, лежащую в основе вычислений, чтобы обеспечить ответственность и возможность внесения обоснованных корректировок. Понимание внутреннего механизма работы модели позволяет специалистам не только доверять ее решениям, но и использовать полученные знания для улучшения качества прогнозирования и адаптации к изменяющимся условиям.
Современные методы анализа временных рядов, включая сложные модели на основе трансформеров, часто не позволяют установить, какие именно моменты во времени оказали наибольшее влияние на итоговый прогноз. Это означает, что, несмотря на высокую точность предсказаний, трудно понять, почему модель пришла к такому выводу. Отсутствие возможности проследить влияние конкретных временных интервалов затрудняет верификацию результатов, выявление потенциальных смещений и, как следствие, ограничивает доверие к модели, особенно в критически важных областях, таких как прогнозирование финансовых рынков или диагностика заболеваний. Неспособность выделить ключевые факторы, определяющие прогноз, препятствует не только улучшению модели, но и извлечению ценной информации из данных, скрытой в динамике временных рядов.
Преодоление непрозрачности моделей временных рядов требует перехода к механической интерпретируемости. Вместо того, чтобы рассматривать модель как единый «черный ящик», данный подход стремится понять внутренние механизмы принятия решений. Это подразумевает детальное изучение того, как конкретные элементы входных данных временного ряда — определенные моменты времени или паттерны — влияют на конечный прогноз. Механическая интерпретируемость позволяет выявить, какие именно части модели отвечают за распознавание определенных временных зависимостей, и как эти зависимости используются для формирования предсказаний. Такой уровень понимания критически важен для повышения доверия к модели, особенно в областях, где ошибки могут иметь серьезные последствия, а также для возможности целенаправленной оптимизации и улучшения её работы. По сути, речь идет о разборе модели «по винтикам», чтобы понять, как именно она «думает» и принимает решения, основываясь на данных временных рядов.

Механическая Интерпретируемость: Причинно-Следственная Модель Временных Рядов
Механическая интерпретируемость (MI) представляет собой набор методов, направленных на исследование внутренних механизмов нейронных сетей не как «черных ящиков», а как совокупность причинно-следственных связей. В отличие от традиционных подходов, фокусирующихся на наблюдении выходных данных или активаций, MI стремится идентифицировать, какие конкретные компоненты сети оказывают причинное влияние на принятие решений. Это достигается путем активного вмешательства во внутренние переменные сети и анализа влияния этих вмешательств на конечный результат. В основе MI лежит концепция рассмотрения нейронных сетей как графа причинно-следственных связей, где каждый узел представляет собой вычислительный элемент, а связи — причинные зависимости между ними. Такой подход позволяет не просто определить, какие части сети активны, но и понять, как именно они способствуют формированию выходного сигнала.
В отличие от методов, ограничивающихся наблюдением весов внимания, таких как Attention Saliency, Mechanistic Interpretability (MI) применяет подходы, активно воздействующие на активации нейронной сети. Вместо пассивного анализа, MI позволяет целенаправленно изменять значения активаций и оценивать влияние этих изменений на выход модели. Этот подход позволяет установить причинно-следственные связи между отдельными компонентами сети и ее предсказаниями, предоставляя более глубокое понимание ее работы, чем простое наблюдение за внутренними переменными.
Метод активационного патчинга, являясь ключевой техникой в рамках механической интерпретируемости (MI), позволяет оценить причинно-следственное влияние отдельных компонентов нейронной сети. Суть метода заключается в замене активаций в ‘испорченном’ (corrupt) образце на активации, полученные из ‘чистого’ (clean) образца, классифицированного верно. Измеряя изменение в выходной вероятности, связанное с этой заменой, можно количественно оценить вклад конкретного компонента в процесс принятия решения моделью. Эффективность патчинга заключается в том, что он позволяет выявить, какие именно активации оказывают наибольшее влияние на выходные данные, и, таким образом, установить причинно-следственные связи внутри сети.
Методика активационного патчинга позволяет построить причинно-следственный граф (Causal Graph), отражающий потоки влияния внутри нейронной сети. В ходе экспериментов было показано, что данный граф способен восстановить до 0.89 вероятности истинного класса в случаях, когда модель ошибочно классифицирует входные данные. Это достигается путем определения, какие активации оказывают наибольшее влияние на итоговый результат, и визуализации этих связей в виде графа, что позволяет анализировать внутреннюю логику принятия решений моделью.

Выявление Временного Влияния: Уровни Активационного Патчинга
Метод активационного патчинга может быть реализован с разной степенью детализации. Патчинг на уровне слоев ($Layer-Level Patching$) предполагает вмешательство в активность целых слоев нейронной сети. Более точным подходом является патчинг на уровне голов внимания ($Head-Level Patching$), позволяющий изолировать влияние отдельных голов в механизме внимания. Наиболее гранулярным уровнем является патчинг на уровне позиций ($Position-Level Patching$), который позволяет анализировать вклад конкретных временных шагов или позиций во входной последовательности. Выбор уровня детализации зависит от целей анализа и необходимой точности идентификации ключевых компонентов модели.
Применение активационного патчинга на различных уровнях детализации — от уровня слоев до уровней отдельных голов внимания и даже позиций во временной последовательности — позволяет изолировать влияние конкретных компонентов или моментов времени на предсказания модели. Это достигается путем выборочного отключения или модификации активаций на определенном уровне, что позволяет оценить, как изменение активности этого компонента влияет на выходные данные. Например, отключение определенной головы внимания позволяет оценить её вклад в процесс классификации, а патчинг на уровне временных шагов позволяет определить, какие моменты времени наиболее важны для конкретного предсказания. Такой подход предоставляет возможность точной диагностики и интерпретации поведения модели.
Систематическое применение методов патчинга активаций на различных уровнях (слои, головы внимания, временные шаги) позволяет определить наиболее критичные головы внимания и временные шаги, оказывающие наибольшее влияние на конкретные классификации. Анализ вклада каждого компонента осуществляется путём последовательного отключения или замены соответствующих активаций и оценки изменения в результатах классификации. Высокая точность, достигаемая на наборе данных Japanese Vowels Dataset (97.57%), подтверждает эффективность данного подхода для выявления ключевых факторов, определяющих поведение модели и её способность к классификации.
Применение методов патчинга активаций на наборе данных японских гласных позволило достичь точности тестирования в 97.57%. Данный результат подтверждает эффективность предложенных интервенций и предоставляет надежную платформу для дальнейшей валидации и анализа влияния различных уровней патчинга — от уровневых до уровневых голов и позиций — на точность классификации. Набор данных японских гласных служит конкретным примером, демонстрирующим практическую применимость и эффективность предложенных методов в задачах анализа и интерпретации моделей машинного обучения.

Разделение Скрытых Признаков с помощью Разреженных Автоэнкодеров
Интеграция разреженных автоэнкодеров с методом взаимной информации (MI) позволяет выявлять скрытые, разделенные признаки внутри архитектуры Time Series Transformer. Данный подход предполагает обучение разреженного кодирования внутренних активаций модели, что способствует выделению независимых составляющих, представляющих различные аспекты временных рядов. Вместо того, чтобы анализировать сложные, переплетенные представления, разреженные автоэнкодеры фокусируются на наиболее значимых активациях, формируя компактный и интерпретируемый код. Благодаря применению MI, удается оценить степень взаимосвязи между этими признаками, определяя те, которые действительно вносят вклад в принятие решений моделью и, таким образом, раскрывая внутреннюю структуру ее знаний. Этот процесс позволяет не только понять, что именно модель «видит» во временных рядах, но и обеспечить более надежную и прозрачную работу, что критически важно для применения в сложных задачах анализа данных.
Изучение разреженных кодов внутренних активаций модели позволяет выявлять временные мотивы — повторяющиеся паттерны в данных, которые могут указывать на фундаментальные процессы, усвоенные системой. Применяя разреженные автоэнкодеры, исследователи стремятся представить сложные активации в виде комбинации небольшого числа активных нейронов, тем самым выделяя наиболее значимые признаки, определяющие поведение модели. Этот подход позволяет не только обнаружить характерные временные структуры, но и получить представление о том, как модель интерпретирует и обрабатывает последовательности данных, раскрывая скрытые механизмы принятия решений и потенциально улучшая возможности обобщения и адаптации к новым задачам. Выделение этих мотивов способствует более глубокому пониманию «мышления» модели и ее способности к извлечению полезной информации из временных рядов.
Использование разреженных автоэнкодеров позволяет выявить, какие внутренние признаки модели Time Series Transformer наиболее существенно влияют на конкретные прогнозы. Этот подход не просто предоставляет информацию о том, что модель предсказывает, но и объясняет почему, подчеркивая наиболее значимые факторы, определяющие результат. Выделение ключевых признаков значительно повышает прозрачность работы модели, позволяя исследователям и пользователям лучше понимать логику принятия решений и оценивать надежность прогнозов. В конечном итоге, подобное улучшение интерпретируемости способствует укреплению доверия к модели и расширению возможностей ее практического применения, особенно в областях, требующих высокой степени обоснованности и ответственности.
Идентификация и понимание скрытых признаков, извлеченных из временных рядов с помощью разреженных автокодировщиков, открывает возможности для целенаправленной оптимизации модели. Понимание того, какие внутренние представления наиболее важны для конкретных прогнозов, позволяет точно настроить архитектуру и параметры модели, избегая неэффективных или избыточных вычислений. Такой подход не только повышает производительность в текущих задачах, но и способствует улучшению обобщающей способности модели на новых, ранее не встречавшихся данных. Вместо слепой оптимизации, основанной на эмпирических результатах, появляется возможность направленного улучшения, учитывающего внутреннюю логику и принципы работы модели, что в конечном итоге приводит к созданию более надежных и эффективных систем анализа временных рядов.
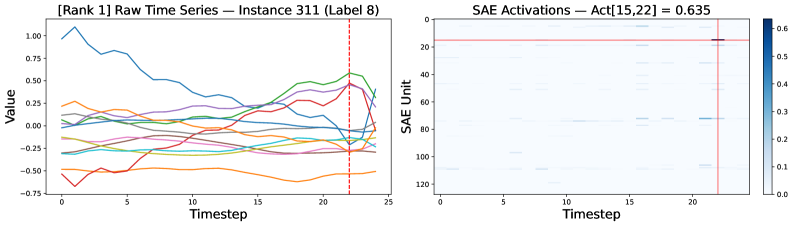
Исследование демонстрирует, что принципы механической интерпретируемости, изначально разработанные для обработки естественного языка, успешно применимы к моделям Time Series Transformer. Авторы, словно проводя вскрытие сложного механизма, выявляют ключевые причинно-следственные связи и скрытые признаки, определяющие решения модели. Этот подход, фокусирующийся на понимании внутренних процессов, а не просто на предсказаниях, позволяет увидеть, как модель интерпретирует временные ряды. Как однажды заметила Грейс Хоппер: «Лучший способ объяснить — это продемонстрировать». Подобно тому, как она стремилась сделать программирование доступным, данная работа нацелена на то, чтобы сделать внутреннюю работу моделей машинного обучения прозрачной и понятной.
Куда Ведет Эта Дорога?
Представленная работа демонстрирует, что инструменты, отточенные на понимании языковых моделей, неожиданно приживаются и во временных рядах. Это не просто перенос технологий; это намек на глубинное единство принципов обработки информации, независимо от её формы. Однако, кажущаяся универсальность методов механической интерпретируемости — лишь верхушка айсберга. Понимание как модель принимает решение, не гарантирует понимания почему она выбрала именно этот путь, особенно когда речь идёт о сложных, многослойных трансформаторах.
Следующим шагом видится не просто выделение ключевых нейронов или патчей активаций, а построение полноценных причинно-следственных моделей. Нужно не просто увидеть, что нейрон активируется, а доказать, что его активация вызывает определенное поведение модели. Использование разреженных автоэнкодеров и анализа внимания — это лишь первые шаги. Предстоит разработка методов, позволяющих “взломать” внутреннюю логику модели, выявить её скрытые предположения и предубеждения. Каждый эксплойт начинается с вопроса, а не с намерения.
В конечном счете, задача состоит не в том, чтобы создать “объяснимый ИИ”, а в том, чтобы понять, что вообще означает “интеллект” в контексте искусственных систем. Понимание механизмов работы моделей — это лишь инструмент, позволяющий углубиться в более фундаментальные вопросы о природе разума и информации. И, возможно, ответы на эти вопросы окажутся куда более неожиданными, чем сама возможность интерпретации сложных алгоритмов.
Оригинал статьи: https://arxiv.org/pdf/2511.21514.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2025-11-28 08:14