Автор: Денис Аветисян
Новое исследование систематизирует ключевые факторы, определяющие точность и универсальность детекторов дипфейков, предлагая практические рекомендации для разработчиков.

Систематическая оценка параметров обучения, методов аугментации данных и стратегий непрерывного обучения для повышения эффективности обнаружения сгенерированного ИИ контента.
Несмотря на активное развитие методов обнаружения дипфейков, их эффективность часто зависит не от архитектуры, а от деталей реализации. В работе ‘Generalized Design Choices for Deepfake Detectors’ систематически исследуется влияние различных проектных решений на точность и обобщающую способность моделей обнаружения дипфейков, включая стратегии обучения, предобработку данных и адаптацию к новым генеративным моделям. Полученные результаты демонстрируют, что определенные техники аугментации, длительность обучения и обработка входных данных стабильно повышают производительность и позволяют достичь передовых показателей на бенчмарке AI-GenBench. Возможно ли, используя эти обобщенные рекомендации, создать универсальные и устойчивые системы обнаружения дипфейков, способные эффективно противостоять постоянно совершенствующимся генеративным моделям?
Растущая Угроза Дипфейков: Вызов для Современного Мира
Распространение изображений, созданных искусственным интеллектом, представляет собой растущую угрозу для доверия к информации и ее целостности. В эпоху, когда визуальный контент доминирует в информационном потоке, способность создавать реалистичные, но ложные изображения и видео подрывает основы общественного доверия к средствам массовой информации и другим источникам информации. Все большее количество поддельных материалов, распространяемых в социальных сетях и онлайн-платформах, может манипулировать общественным мнением, влиять на политические процессы и даже приводить к серьезным социальным последствиям. Это требует разработки новых методов и технологий для выявления и противодействия дезинформации, создаваемой с помощью ИИ, и повышения осведомленности общественности о рисках, связанных с цифровыми подделками.
Существующие методы обнаружения подделок, основанные на анализе артефактов и несоответствий в изображениях и видео, всё чаще оказываются неэффективными перед лицом стремительного развития генеративных моделей искусственного интеллекта. Традиционные алгоритмы, успешно выявлявшие манипуляции ранее, испытывают трудности с распознаванием всё более реалистичных и сложных подделок, создаваемых современными нейросетями. Проблема усугубляется тем, что генеративные модели постоянно совершенствуются, адаптируясь к новым методам обнаружения и обходя их, что требует постоянной разработки и внедрения новых, более совершенных подходов к верификации контента. Этот технологический «гонка вооружений» между создателями и детекторами дипфейков представляет серьезную угрозу для достоверности информации и доверия к визуальному контенту в цифровой среде.
Эффективное выявление дипфейков требует разработки моделей, способных к обобщению и устойчивости к намеренным искажениям. Современные алгоритмы часто демонстрируют высокую точность на обучающих данных, но их эффективность резко снижается при столкновении с манипуляциями, не представленными в процессе обучения. Для решения этой проблемы исследователи сосредотачиваются на создании моделей, способных выявлять закономерности, лежащие в основе дипфейков, а не просто запоминать конкретные артефакты. Особое внимание уделяется устойчивости к так называемым “атакам противника” — преднамеренным изменениям во входных данных, направленным на обход системы обнаружения. Успешная реализация подобного подхода позволит создавать надежные инструменты для защиты от дезинформации и поддержания доверия к визуальному контенту в цифровой среде.
Использование Предварительно Обученных Визуальных Моделей: Фундамент для Обнаружения
Использование предварительно обученных моделей, таких как ResNet-50 CLIP, ViT-L CLIP и DINOv2, является эффективной основой для обнаружения дипфейков. Эти модели, обученные на огромных объемах данных, позволяют получить надежные признаки, применимые к различным типам изображений. В отличие от обучения с нуля, применение трансферного обучения значительно сокращает время обучения и позволяет достичь более высокой производительности на начальных этапах, поскольку модели уже обладают способностью выделять значимые визуальные характеристики. CLIP и DINOv2, в частности, обучались на задачах сопоставления изображений и текста, что способствует извлечению семантически значимых признаков, полезных для выявления манипуляций с изображениями.
Предварительно обученные модели, такие как ResNet-50, CLIP, ViT-L и DINOv2, демонстрируют высокую эффективность благодаря извлечению устойчивых признаков из изображений. Обучение на масштабных наборах данных, включающих миллионы изображений различного происхождения и содержания, позволило этим моделям сформировать обобщенные представления об визуальных особенностях. Это обеспечивает возможность успешного применения полученных признаков к разнообразным типам изображений, включая фотографии, графику и видеокадры, и служит надежной основой для решения задач, связанных с анализом и классификацией изображений, даже при ограниченном объеме данных для конкретной задачи.
Тонкая настройка предварительно обученных моделей, таких как ResNet-50, CLIP, ViT-L CLIP и DINOv2, на специализированных наборах данных с дипфейками позволяет значительно ускорить процесс обучения и повысить начальную производительность системы обнаружения подделок. Вместо обучения модели с нуля, этот подход использует знания, уже полученные моделью при обучении на больших объемах данных, что сокращает время, необходимое для достижения приемлемой точности. Более того, тонкая настройка часто приводит к лучшим результатам, особенно при ограниченном объеме обучающих данных для дипфейков, поскольку модель уже обладает способностью извлекать релевантные признаки из изображений.
Многоклассовое обучение, включающее идентификацию генератора, значительно повышает способность модели различать источники подделок. Вместо бинарной классификации (подделка/не подделка), модель обучается распознавать конкретные алгоритмы или инструменты, использованные для создания дипфейков. Это достигается путем включения в обучающую выборку данных, помеченных не только как «подделка», но и с указанием конкретного генератора (например, StyleGAN2, DeepFaceLab и т.д.). Такой подход позволяет модели не просто обнаруживать манипуляции с изображениями, но и идентифицировать используемый метод, что критически важно для анализа и атрибуции дипфейков, а также для разработки более эффективных методов противодействия.
Непрерывное Обучение: Преодоление Катакстрофического Забывания
Непрерывное обучение (continual learning) решает проблему сохранения производительности модели на ранее изученных задачах при адаптации к новым данным. Традиционные модели машинного обучения склонны к “катастрофическому забыванию” — резкому снижению эффективности на старых задачах после обучения на новых. Непрерывное обучение направлено на преодоление этого ограничения, позволяя модели последовательно осваивать новые знания без существенной потери эффективности на уже освоенных задачах. Это достигается путем разработки методов, которые позволяют модели сохранять и использовать информацию из предыдущих задач при обучении на новых данных, обеспечивая постоянное накопление знаний и адаптацию к изменяющейся среде.
Буферы воспроизведения (replay buffers) представляют собой ключевой механизм смягчения катастрофического забывания в задачах непрерывного обучения. Они функционируют как хранилища предыдущего опыта, состоящего из пар «вход-выход», полученных при решении предыдущих задач. В процессе обучения на новых данных, модели периодически воспроизводят (replay) эти сохраненные примеры, что позволяет ей удерживать знания о предыдущих задачах. Эффективность буферов воспроизведения зависит от их размера и стратегии выбора примеров для воспроизведения, при этом более крупные буферы и более продуманные стратегии обычно приводят к лучшему сохранению знаний, но и требуют больше вычислительных ресурсов. Использование буферов воспроизведения позволяет модели избегать полной перезаписи весов, что характерно для традиционного обучения, и тем самым сохранять работоспособность на ранее изученных задачах.
Метод гармоничного воспроизведения (Harmonic replay) представляет собой стратегию, позволяющую достичь производительности, сопоставимой с полной перетренировкой модели ($100\%$ производительность), при значительно меньших вычислительных затратах. В отличие от традиционных методов воспроизведения, которые случайным образом выбирают примеры из буфера памяти, гармоничное воспроизведение динамически взвешивает важность каждого примера, основываясь на его вкладе в поддержание производительности на ранее изученных задачах. Это достигается путем анализа градиентов потерь для каждого примера и использования этих данных для формирования весов. В результате, модель фокусируется на наиболее информативных примерах, сокращая объем необходимых вычислений и обеспечивая эффективное удержание знаний при обучении новым данным.
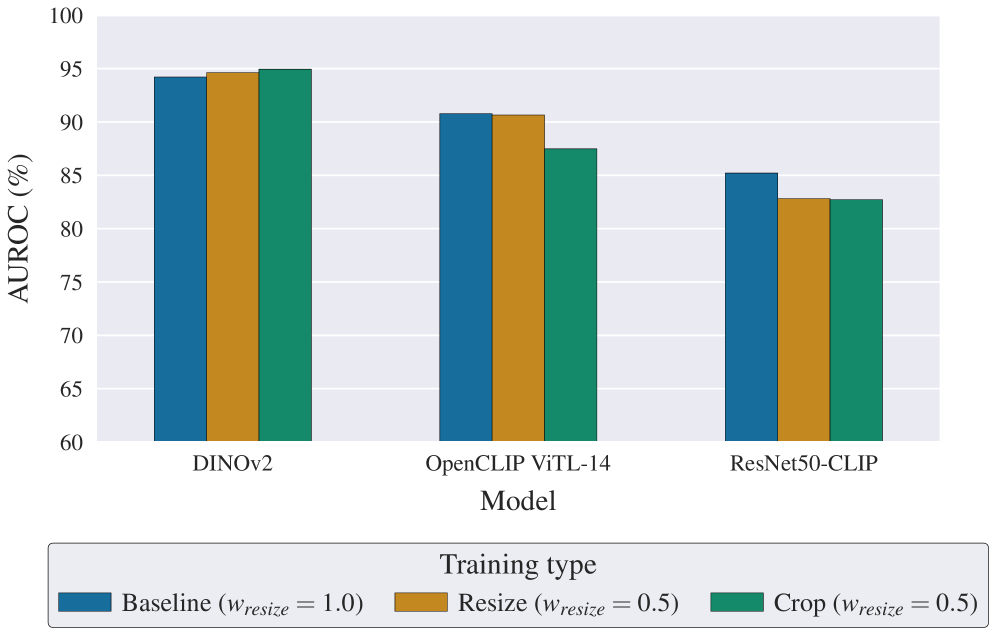
Бинарная классификация и применение методов аугментации данных, таких как сжатие JPEG и случайная обрезка (random cropping), позволяют повысить устойчивость и обобщающую способность моделей при непрерывном обучении. Использование бинарной классификации в качестве вспомогательной задачи способствует сохранению важных признаков, полученных на предыдущих этапах обучения. Аугментация данных, в частности сжатие JPEG, имитирует реальные условия получения изображений с потерями, что повышает устойчивость модели к шуму и артефактам. Случайная обрезка увеличивает разнообразие обучающей выборки, заставляя модель учиться извлекать инвариантные признаки, не зависящие от точного положения объекта на изображении. Комбинация этих методов позволяет модели лучше адаптироваться к новым данным, не забывая при этом предыдущие знания.

AI-GenBench: Динамический Фреймворк Оценки для Новой Эры Дипфейков
Бенчмарк AI-GenBench создан для имитации постоянно меняющегося ландшафта генераторов дипфейков, что делает оценку систем обнаружения более реалистичной и сложной. В отличие от традиционных подходов, использующих фиксированный набор дипфейков, AI-GenBench динамически добавляет новые, ранее не встречавшиеся подделки во время оценки. Это позволяет проверить способность моделей адаптироваться к постоянно совершенствующимся технологиям создания подделок и поддерживать высокую точность обнаружения даже в условиях, когда дипфейки становятся все более изощренными. Такой подход позволяет получить более объективную и надежную оценку эффективности различных методов обнаружения дипфейков, приближая ее к реальным сценариям использования.
В рамках AI-GenBench реализована уникальная методология оценки, позволяющая проверить способность моделей обнаружения дипфейков адаптироваться к постоянно меняющемуся ландшафту поддельных изображений и видео. В отличие от традиционных статических бенчмарков, AI-GenBench динамически вводит новые генераторы дипфейков в процессе оценки. Это позволяет выявить, насколько эффективно модель сохраняет высокую производительность при столкновении с ранее неизвестными методами подделки. Такая динамическая оценка особенно важна, поскольку злоумышленники постоянно совершенствуют свои инструменты, создавая всё более реалистичные и сложные подделки, способные обмануть существующие системы обнаружения. Способность модели к адаптации и поддержанию стабильной работы в условиях постоянно меняющихся угроз является ключевым показателем её надежности и практической применимости.
Разработанная методология оценки, основанная на AI-GenBench, представляет собой стандартизированный подход к сопоставлению различных методов обнаружения дипфейков. Эта система позволяет исследователям объективно сравнивать эффективность различных алгоритмов, используя единый набор данных и протокол оценки. Вместо оценки на статичных наборах данных, эта методика позволяет оценивать устойчивость моделей к новым, постоянно эволюционирующим подделкам. Благодаря унифицированному процессу, исследователи могут более точно определить сильные и слабые стороны различных подходов к обнаружению дипфейков, способствуя развитию более надежных и адаптивных систем защиты от манипулированных изображений и видео.
В ходе исследования была достигнута передовая результативность в области обнаружения дипфейков, зафиксирована средняя площадь под ROC-кривой (AUROC) в 97.36% на бенчмарке AI-GenBench. Такой результат стал возможен благодаря интеграции оптимизированных практик разработки: использовался четырехэпохочный режим обучения, применялась аугментация данных, основанная на результатах оценки, и проводилось изменение размера изображений до полного разрешения с использованием архитектуры DINOv2 в качестве основы. Данный подход позволил значительно повысить устойчивость модели к новым, ранее не встречавшимся подделкам, демонстрируя ее способность к адаптации и поддержанию высокой точности в динамично меняющихся условиях.

Исследование подходов к обнаружению дипфейков демонстрирует, что систематическая оценка проектных решений, таких как аугментация данных и продолжительность обучения, позволяет значительно повысить производительность и обобщающую способность детекторов. Этот процесс напоминает непрерывный цикл: наблюдение за данными, формулирование гипотез о наиболее эффективных методах, эксперименты с различными подходами и анализ полученных результатов. Как заметила Фэй-Фэй Ли: «Искусственный интеллект — это не просто технология, это способ понимания мира». Применительно к данной работе, это понимание достигается через тщательное изучение закономерностей в визуальных данных и разработку алгоритмов, способных выявлять манипуляции с ними. Особое внимание уделяется подходу непрерывного обучения, позволяющему адаптивно обновлять детекторы с появлением новых генеративных моделей, что подчеркивает динамичный характер исследований в этой области.
Куда двигаться дальше?
Исследование закономерностей в проектировании детекторов дипфейков выявило устойчивые преимущества определенных подходов к аугментации данных, длительности обучения и предварительной обработке входных сигналов. Однако, кажущаяся универсальность этих решений — лишь приглашение к более глубокому пониманию. Остается открытым вопрос: действительно ли мы оптимизируем детекторы, или просто создаем более сложные фильтры, неспособные к адаптации к принципиально новым методам генерации? Успех replay-based continual learning обнадеживает, но не решает проблему «забывания» и требует дальнейшей разработки механизмов сохранения ключевых знаний.
Особый интерес представляет изучение пределов обобщающей способности детекторов. Как далеко можно выйти, используя существующие подходы к аугментации, прежде чем потребуется принципиально новый взгляд на проблему? Вероятно, ключ лежит не в увеличении объема данных, а в создании моделей, способных к мета-обучению — то есть к обучению способам адаптации к новым, ранее невиданным дипфейкам.
В конечном итоге, поиск эффективных детекторов дипфейков — это не просто техническая задача. Это исследование самой природы восприятия и доверия. Ошибка модели — не провал, а указание на пробел в нашем понимании. Именно в этих ошибках, в несоответствиях между алгоритмической логикой и человеческим восприятием, и кроется путь к более глубокому осознанию реальности.
Оригинал статьи: https://arxiv.org/pdf/2511.21507.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- H ПРОГНОЗ. H криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
2025-11-27 22:00