Автор: Денис Аветисян
В статье представлен обзор перспективного направления исследований, направленного на понимание внутренних механизмов работы нейронных сетей.
Механическая интерпретируемость как инструмент для анализа и понимания алгоритмических принципов работы нейронных сетей.
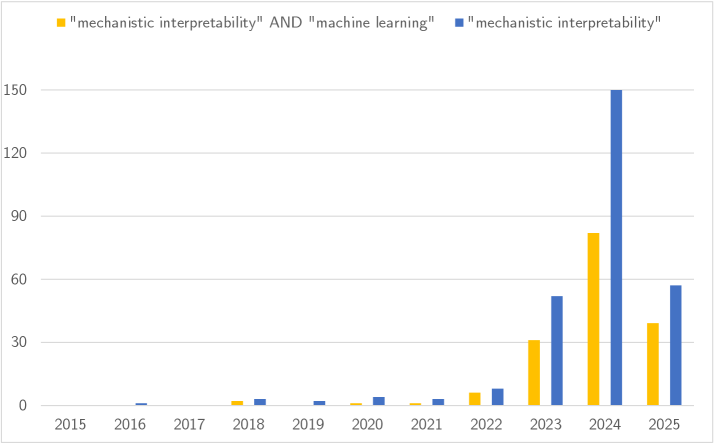
Несмотря на впечатляющие успехи, глубокие нейронные сети остаются «черными ящиками», затрудняя понимание принципов их работы. В статье «Unboxing the Black Box: Mechanistic Interpretability for Algorithmic Understanding of Neural Networks» представлен всесторонний обзор механической интерпретируемости (MI) — подхода, направленного на раскрытие внутренних вычислений нейронных сетей и перевод их в понятные человеку алгоритмы. MI позволяет не только предсказывать выходные данные, но и понимать, как эти данные формируются, предлагая принципиально новый взгляд на изучение моделей машинного обучения. Сможет ли механическая интерпретируемость превратить нейронные сети из эмпирических инструментов в системы, доступные для научного анализа и предсказания?
Чёрный Ящик Глубокого Обучения: Пределы Понимания
Несмотря на впечатляющие достижения в различных областях, глубокие нейронные сети, особенно крупные фундаментальные модели, остаются во многом непрозрачными, что серьезно ограничивает доверие к ним и возможность контроля над их работой. Эта «черноящичность» представляет собой значительную проблему, поскольку сложно понять, какие именно факторы и внутренние механизмы приводят к конкретному решению или прогнозу. В отличие от традиционных алгоритмов, где логика работы относительно ясна, внутренние представления и преобразования данных в глубоких сетях зачастую скрыты и сложны для интерпретации. Отсутствие прозрачности затрудняет выявление и исправление ошибок, а также оценку надежности и безопасности этих моделей, особенно в критически важных приложениях, таких как медицина или финансы, где любое неверное решение может иметь серьезные последствия.
Непрозрачность глубоких нейронных сетей представляет значительные риски при их применении в критически важных областях. Отсутствие понимания механизмов принятия решений моделями вызывает опасения относительно предвзятости, особенно в задачах, связанных с оценкой кредитоспособности или определением рисков в правоохранительной деятельности, где даже незначительные смещения могут привести к несправедливым результатам. Кроме того, эта непрозрачность создает уязвимости в сфере безопасности, поскольку сложно предсказать, как модель отреагирует на намеренно искаженные входные данные или новые, непредсказуемые ситуации. В конечном итоге, невозможность объяснить логику работы модели приводит к непредвиденным последствиям, затрудняет выявление и исправление ошибок, а также препятствует ответственному и этичному использованию искусственного интеллекта в обществе.
Традиционные методы анализа оказываются недостаточно эффективными для понимания процессов, происходящих внутри глубоких нейронных сетей. В отличие от алгоритмов, где логика принятия решений четко прослеживается, сложные модели, такие как большие языковые модели, оперируют с огромным количеством параметров, что делает невозможным однозначное определение причинно-следственных связей между входными данными и выходным результатом. Это затрудняет отладку и исправление ошибок, поскольку неясно, какие именно элементы модели приводят к нежелательному поведению. Кроме того, отсутствие прозрачности ограничивает возможности верификации и подтверждения корректности работы, что особенно критично в областях, связанных с безопасностью и ответственностью, где необходимо гарантировать надежность и предсказуемость принимаемых решений. Таким образом, ограниченность существующих методов интерпретации представляет собой серьезное препятствие для широкого и безопасного применения технологий глубокого обучения.
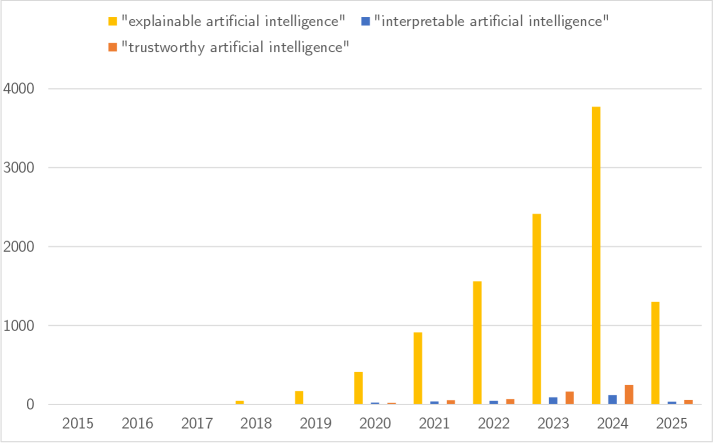
Механическая Интерпретируемость: Разбирая Разум По Частям
Механическая интерпретируемость представляет собой перспективный подход к анализу нейронных сетей, ориентированный на выявление алгоритмов, реализованных внутри них. В отличие от традиционных методов, фокусирующихся на входных и выходных данных, этот подход направлен на деконструкцию внутренней работы сети — на определение конкретных вычислений, выполняемых отдельными нейронами и цепями. Это предполагает анализ весов, активаций и архитектуры сети для построения модели того, как сеть решает поставленную задачу, а не просто констатацию факта, что она это делает. Понимание реализованных алгоритмов позволяет не только объяснить поведение модели, но и предсказать его в новых ситуациях, а также выявить потенциальные уязвимости и ошибки.
Анализ вычислений, выполняемых отдельными нейронами и нейронными цепями, позволяет перейти от простого наблюдения за поведением нейронной сети к пониманию лежащих в его основе механизмов. Этот подход предполагает детальное исследование функций отдельных нейронов — какие входные данные они обрабатывают, какие преобразования выполняют и как их выходные сигналы влияют на работу других элементов сети. Вместо рассмотрения сети как «черного ящика», исследователи стремятся идентифицировать и описать конкретные алгоритмы, реализованные внутри, определяя, какие операции выполняются и как они взаимодействуют друг с другом для достижения определенного результата. Такой подход позволяет получить более глубокое понимание принципов работы модели, чем простое сопоставление входных и выходных данных.
Метод Circuit Discovery предполагает выявление и анализ функциональных подсетей внутри нейронных сетей. Этот процесс включает в себя определение взаимосвязей между отдельными нейронами и выявление специфических вычислений, которые они выполняют совместно. В результате, удается идентифицировать модули, отвечающие за конкретные функции, такие как обнаружение границ, распознавание объектов или обработка определенных типов входных данных. Анализ этих подсетей позволяет составить карту внутренних вычислений модели, определяя, как различные компоненты взаимодействуют для достижения определенного результата. Данный подход использует алгоритмы декомпозиции и визуализации для представления сложных сетей в виде более понятных и интерпретируемых структур.
Понимание внутренней логики моделей искусственного интеллекта является критически важным для создания надежных, безопасных и заслуживающих доверия систем. Отсутствие прозрачности в процессах принятия решений нейронными сетями представляет значительный риск в критически важных приложениях, таких как автономное вождение, медицинская диагностика и финансовое моделирование. Анализ и верификация алгоритмов, реализуемых внутри этих моделей, позволяет выявлять и устранять потенциальные уязвимости, предвзятости и нежелательное поведение. Это, в свою очередь, способствует повышению устойчивости систем к манипуляциям, а также обеспечивает возможность предсказуемого и контролируемого функционирования, что необходимо для широкого внедрения и общественного доверия к технологиям ИИ.
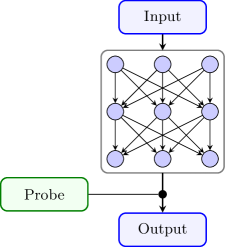
Декодирование Внутренних Представлений: Разделение Факторов Вариативности
Основная сложность в декодировании внутренних представлений нейронных сетей заключается в разделении факторов вариации, закодированных в активациях нейронов. Нейроны редко кодируют только один аспект входных данных; вместо этого, активация одного нейрона обычно представляет собой комбинацию нескольких факторов, таких как положение объекта, его цвет, форма или ориентация. Эта проблема, известная как перекрытие признаков, затрудняет интерпретацию внутренних представлений и понимание того, как сеть обрабатывает информацию. Разделение этих факторов вариации необходимо для построения более интерпретируемых и контролируемых моделей, а также для понимания принципов работы биологических нейронных сетей.
Разреженные автокодировщики (Sparse Autoencoders) представляют собой метод обучения нейронных сетей, направленный на выявление и изоляцию отдельных признаков, закодированных в данных. В процессе обучения, эти автокодировщики используют регуляризацию для стимулирования разреженности активаций скрытых слоев, то есть, большинство нейронов в скрытом слое должны быть неактивны для данного входного сигнала. Это приводит к тому, что каждый нейрон специализируется на представлении конкретного признака, что упрощает интерпретацию сложных представлений, формируемых сетью. Эффективность метода заключается в способности сети автоматически выделять наиболее значимые признаки, минимизируя влияние избыточной информации и шума, что позволяет более четко понимать, какие аспекты входных данных влияют на выходные данные.
Явление суперпозиции представляет собой значительную сложность при разделении факторов вариативности, закодированных в нейронных активациях. Суть суперпозиции заключается в том, что отдельные нейроны часто кодируют не один, а сразу несколько различных признаков или аспектов входных данных. Это означает, что активация одного нейрона не может быть однозначно интерпретирована как отражение конкретного признака, что затрудняет выделение и изоляцию отдельных признаков в процессе декодирования внутренних представлений. Вследствие суперпозиции, для определения вклада каждого признака необходимо учитывать комбинацию активаций множества нейронов, что значительно усложняет анализ и интерпретацию нейронных сетей.
Метод активационного патчинга (Activation Patching) позволяет выявлять критически важные нейроны внутри нейронных сетей, анализируя влияние их активаций на выходные данные. Суть метода заключается в замене активаций отдельных нейронов в слое на активации из другого входного примера, что позволяет оценить вклад каждого нейрона в формирование конкретных признаков или ответов сети. Путем последовательной замены активаций и отслеживания изменений в выходных данных, можно проследить путь информации через сеть и понять, как она преобразуется на различных этапах обработки. Этот подход особенно полезен для анализа сложных и глубоких сетей, где трудно понять, какие конкретно нейроны отвечают за определенные функции или признаки.

За Пределами Интерпретируемости: Надёжность, Конфиденциальность и Контроль
Механическая интерпретируемость — это не только теоретическое исследование, но и практический инструмент повышения надёжности моделей. Анализ внутренних механизмов позволяет выявлять уязвимости, которые могут приводить к неожиданным ошибкам или предвзятости в работе системы. Вместо простого исправления внешних проявлений, такой подход даёт возможность устранить причины этих проблем, модифицируя конкретные компоненты модели. Это особенно важно для критически важных приложений, где даже незначительные сбои могут иметь серьёзные последствия, например, в системах автономного вождения или медицинской диагностике. Понимание того, как модель принимает решения на уровне отдельных нейронов и связей, открывает путь к созданию более устойчивых и предсказуемых алгоритмов.
Механистическая интерпретируемость открывает новые возможности для защиты конфиденциальности данных, используемых при обучении моделей. Исследования показывают, что модели машинного обучения могут неявно запоминать информацию из обучающей выборки, создавая риск несанкционированного раскрытия личных или конфиденциальных данных. Анализ внутренних механизмов модели позволяет выявить и подтвердить, что модель действительно извлекает и использует чувствительную информацию, или, наоборот, убедиться в её отсутствии. Этот подход позволяет верифицировать, что модель обобщает знания, а не просто воспроизводит данные, что значительно повышает уровень защиты конфиденциальности и способствует соблюдению требований к обработке персональных данных.
Возможность непосредственного редактирования внутренних компонентов модели открывает принципиально новые перспективы в управлении искусственным интеллектом. Вместо переобучения всей сети для исправления ошибок или адаптации к меняющимся условиям, становится возможным точечное вмешательство в ее структуру. Исследователи демонстрируют, что, идентифицируя конкретные нейроны или связи, ответственные за определенные функции, можно аккуратно изменить их поведение, не затрагивая общую производительность модели. Это позволяет оперативно корректировать нежелательные результаты, устранять предвзятости и даже внедрять новые знания, значительно повышая гибкость и надежность алгоритмических систем. Такой подход к модификации моделей обеспечивает беспрецедентный уровень контроля и открывает путь к созданию действительно адаптивных и персонализированных интеллектуальных систем.
Переход к механической интерпретируемости знаменует собой фундаментальный сдвиг в парадигме работы с алгоритмами. Если ранее модели машинного обучения представляли собой непрозрачные “черные ящики”, выдающие прогнозы без объяснений, то теперь фокус смещается в сторону создания прозрачных и контролируемых систем. Это означает возможность не просто предсказывать результаты, но и понимать, как модель пришла к этим результатам, а главное — иметь возможность целенаправленно изменять ее внутренние механизмы для исправления ошибок или адаптации к новым задачам. Такой подход позволяет перейти от пассивного использования алгоритмов к активному управлению ими, открывая новые горизонты в области искусственного интеллекта и обеспечивая большую надежность и безопасность систем.
Изучение механистической интерпретируемости нейронных сетей, как представлено в работе, неизбежно напоминает попытки разобраться в запутанном механизме, где каждая деталь, казалось бы, логична сама по себе, но в совокупности порождает непредсказуемые результаты. В этом контексте вспоминается высказывание Джона фон Неймана: «В науке не бывает окончательных ответов, только лучшие на данный момент». Подобно исследованию «черного ящика», каждый новый уровень понимания внутренней работы сети лишь демонстрирует сложность и неполноту наших знаний. Обещания самовосстанавливающихся систем кажутся особенно наивными; ведь, как показывает практика, любая сложная система рано или поздно выйдет из строя, а «feature disentanglement» — это лишь отсрочка неизбежного. И если баг воспроизводится, это не признак стабильности, а лишь подтверждение того, что мы нашли способ его задокументировать.
Что дальше?
Рассмотренные методы механической интерпретируемости, безусловно, представляют интерес. Однако, наивно полагать, что «разобрав» нейронную сеть, удастся найти там нечто принципиально новое. Скорее, обнаружится изощрённая реализация давно известных алгоритмов, замаскированных под слои нелинейных преобразований. Продакшен, как всегда, найдёт способ использовать эти «открытия» для создания ещё более непрозрачных систем, которые будут казаться умными, но работать как чёрный ящик, только с более сложной обёрткой.
Одержимость поиском «чистых» признаков и каузальных связей, вероятно, обречена на разочарование. Нейронные сети, особенно глубокие, по своей природе склонны к суперпозиции и перекрытию представлений. Разделение этих представлений — это искусственная задача, навязанная человеческим стремлением к порядку. В конечном итоге, «объяснимый ИИ» может оказаться просто более сложным способом скрыть истинную сложность алгоритма.
Вместо того, чтобы пытаться понять, как сеть принимает решения, возможно, более продуктивным будет сосредоточиться на предсказании её ошибок. Ведь в конечном счете, главное — не объяснить, а исправить. А там, глядишь, и элегантная теория сама собой появится — когда станет понятно, что всё новое — это старое, только с другим именем и теми же багами.
Оригинал статьи: https://arxiv.org/pdf/2511.19265.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2025-11-26 00:45